[자연어처리] 번역기 프로그램 만들기
2020. 5. 14. 12:09ㆍ노트/Python : 프로그래밍

데이터
Tab-delimited Bilingual Sentence Pairs from the Tatoeba Project (Good for Anki and Similar Flashcard Applications)
Introducing Anki If you don't already use Anki, vist the website at http://ankisrs.net/ to download this free application for Macintosh, Windows or Linux. About These Files Any flashcard program that can import tab-delimited text files, such as Anki (free)
www.manythings.org

위 사이트에 접속하여 French - English 데이터를 다운로드
import pandas as pd
import numpy as np
df= pd.read_csv(path+"fra.txt", sep="\t", names=["eng","fra"], index_col=False)
df=df[0:70000]
df.sample(20)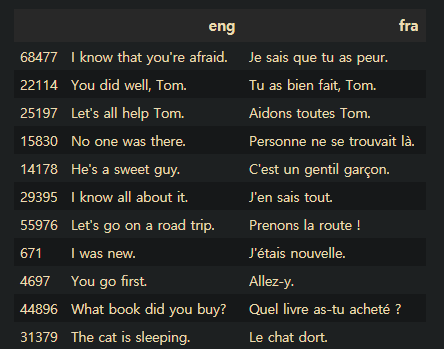
# fra 열 전체에 대해 아래와 같은 시그널 추가
# start : "\t " , stop : " \n"
# ex) Rattrape-le => \t Rattrape -le. \n
for i in range(len(df["fra"])):
df["fra"][i]=str("\t "+df["fra"][i]+" \n")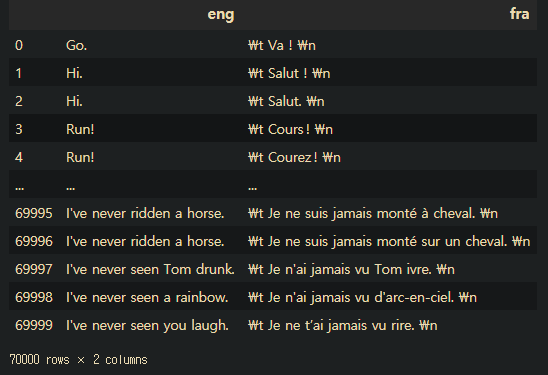
토큰화
# 글자단위 토큰화
engVocab = set()
fraVocab = set()
for line in df.eng:
for c in line:
engVocab.add(c)
for line in df.fra:
for c in line:
fraVocab.add(c)
engVocabSize=len(engVocab)+1
fraVocabSize=len(fraVocab)+1
# set은 다루기어려워 리스트로 자료구조 변경
engVocab = sorted(list(engVocab))
fraVocab = sorted(list(fraVocab))
engToIndex= dict([(c,i+1) for i , c in enumerate(engVocab)])
fraToIndex= dict([(c,i+1) for i , c in enumerate(fraVocab)])
인코딩
# 영어 문장 인코딩
encoderInput=[]
for li in df.eng :
t=[]
for c in li :
t.append(engToIndex[c])
encoderInput.append(t)
print(encoderInput[:10])
# 프랑스어 문장 => 정수 인코딩
decoderInput=[]
for li in df.fra:
t=[]
for c in li:
t.append(fraToIndex[c])
decoderInput.append(t)
print(decoderInput[:10])
# 프랑스어 문장 인코딩 \t 제거
decoderFra=[]
for li in df.fra :
t=[]
i=0
for c in li :
if i >0: # \t 를 제거하기 위해
t.append(fraToIndex[c])
i=i+1
decoderFra.append(t)
print(decoderFra[:10])
패딩
# 문장 -> 정수 변환 -> 패딩
# 패딩 : 각 언어별로 가장 긴 글자로 구성된 문장 길이로 통일 하는 작업
maxEngLen= max([len(li) for li in df.eng ])
maxFraLen= max([len(li) for li in df.fra ])
# 각 문자의 문자길이 중 최대 길이
from keras.preprocessing.sequence import pad_sequences
encoderInput = pad_sequences(encoderInput, maxlen=maxEngLen, padding="post")
decoderInput = pad_sequences(decoderInput, maxlen=maxFraLen, padding="post")
decoderFra= pad_sequences(decoderFra, maxlen=maxFraLen, padding="post")
from keras.utils import to_categorical
encoderInput=to_categorical(encoderInput)
decoderInput=to_categorical(decoderInput)
decoderFra=to_categorical(decoderFra)
np.shape(encoderInput) #(70000, 26, 80)
#(70000줄 , 전체 줄여서 최대 글자수, 글자 종류)
np.shape(decoderInput) #(70000, 76, 106)
#(70000줄 , 전체 줄여서 최대 글자수, 글자 종류)
모델 생성
# 트레이닝시 이전 상태의 실제값을 현재상태의 디코더 입력으로 해야함.
# ( 예측값으로 하면 안됌 )
from keras.layers import Input, Embedding, Dense , LSTM
from keras.models import Model
# ex) Input(shape=(50,1))
# feature : 1개, time-step(시점) : 50개
# lt = LSTM(출력)(ip)
# d1 = Dense(10, activation="relu")(lt)
# d2 = Dense(1, activation="sigmoid")(d1)
# Model ( inputs =ip, outputs=d2)
encoderInputs = Input(shape=(None, engVocabSize))
decoderInputs = Input(shape=(None, fraVocabSize))
# 디코더 입력 = Input(None(maxFraLen), 프랑스어 문자 종류 수)
# 인코더 LSTM 셀
encoderLSTM = LSTM(units=256, return_state=True)
# return_state=True : 인코더의 마지막 상태 정보를 디코더의 입력 상태 정보로 전달 옵션
# 디코더 LSTM 셀
decoderLSTM = LSTM(units=256, return_sequences=True, return_state=True)
# 인코더 LSTM셀의 입력 정의
_, stateH, stateC = encoderLSTM(encoderInputs) # _, 히든상태(위), 셀상태(오른쪽)
encoderStates = [stateH, stateC] # 컨텍스트 벡터
decoderOutputs, _, _ = decoderLSTM(decoderInputs, initial_state=encoderStates)
decoderSoftmax = Dense(fraVocabSize, activation="softmax")
decoderOutputs = decoderSoftmax(decoderOutputs)
model = Model(inputs=[encoderInputs,decoderInputs], outputs=decoderOutputs)
model.summary()
>>>
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, None, 80) 0
__________________________________________________________________________________________________
input_2 (InputLayer) (None, None, 106) 0
__________________________________________________________________________________________________
lstm_1 (LSTM) [(None, 256), (None, 345088 input_1[0][0]
__________________________________________________________________________________________________
lstm_2 (LSTM) [(None, None, 256), 371712 input_2[0][0]
lstm_1[0][1]
lstm_1[0][2]
__________________________________________________________________________________________________
dense_1 (Dense) (None, None, 106) 27242 lstm_2[0][0]
==================================================================================================
Total params: 744,042
Trainable params: 744,042
Non-trainable params: 0
__________________________________________________________________________________________________
모델 학습
model.compile(optimizer="rmsprop", loss="categorical_crossentropy")
model.fit(x=[encoderInput,decoderInput], y=decoderFra, batch_size=64, epochs=50, validation_split=0.2)
# 모델 저장
model.save("train.h5")
# 모델 불러오기
from keras.models import load_model
model = load_model('train.h5')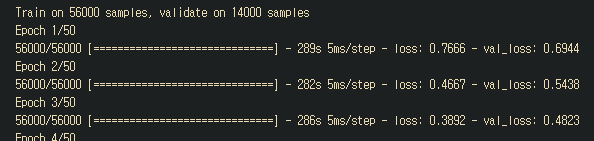
encoderModel = Model(inputs = encoderInputs, outputs = encoderStates)
indexToEng = dict((i,c ) for c , i in engToIndex.items())
indexToFra = dict((i,c ) for c , i in fraToIndex.items())
- seq2seq 동작
1)입력 문장 -> 인코더 -> 은닉 상태, 셀 상태 얻어냄
2)상태정보와 Start 시그널("\t")을 디코더로 전달
3)다음 문자를 예측(stop 시그널("\n")이 등장할때 까지) 반복
디코더
# 디코더
decoderStateInputHidden = Input(shape=(256,))
decoderStateInputCell = Input(shape=(256,))
decoderStateInputs = [decoderStateInputHidden, decoderStateInputCell]
decoderOutputs, stateHidden, stateCell = decoderLSTM(decoderInputs, initial_state = decoderStateInputs)
decoderStates = [stateHidden, stateCell]
decoderOutputs = decoderSoftmax(decoderOutputs)
decoderModel = Model(inputs=[decoderInputs]+decoderStateInputs, outputs=[decoderOutputs]+decoderStates)
번역 함수
def decodeSeq(inputSeq): # (1, 26, 80)
statesValue = encoderModel.predict(inputSeq)
# print(statesValue)
# print(np.shape(statesValue))
targetSeq = np.zeros((1,1,fraVocabSize)) # 1,1,106
targetSeq[0,0,fraToIndex['\t']] = 1 # 원핫인코딩
stop = False
decodedSent=""
while not stop: # "\n"문자를 만날때까지 반복
output, h, c = decoderModel.predict([targetSeq]+statesValue)
# 예측값을 프랑스 문자로 변환
tokenIndex = np.argmax(output[0,-1,:])
predChar = indexToFra[tokenIndex]
# 현시점 예측문자가 예측문장에 추가
decodedSent+=predChar
if (predChar=="\n" or len(decodedSent)>maxFraLen):
stop = True
# 현시점 예측결과가 다음 시점에 입력으로
targetSeq = np.zeros((1,1,fraVocabSize))
targetSeq[0,0,tokenIndex] = 1
# 현시점 상태를 다음 시점 상태로 사용
statesValue = [h,c]
return decodedSent # 번역결과
번역 결과
for seqIndex in [1,50,100,200,300]:
inputSeq = encoderInput[seqIndex:seqIndex+1]
# print(np.shape(inputSeq)) # (1, 26, 80)
decodedSeq = decodeSeq(inputSeq)
print("입력문장:", df.eng[seqIndex])
print("정답:", df.fra[seqIndex][1:len(df.fra[seqIndex])-1]) # "\t", "\n" 제거
print("번역기:", decodedSeq[:len(decodedSeq)-1])
print("\n")
'노트 > Python : 프로그래밍' 카테고리의 다른 글
| [자연어처리] 문장 생성하기 (text generation) (0) | 2020.05.18 |
|---|---|
| [자연어처리] word2vec 로 워드임베딩 하기 (0) | 2020.05.18 |
| [자연어처리] 케라스로 단어사전 만들기 (0) | 2020.05.08 |
| [신경망] LSTM을 이용한 "나비야" 작곡하기 코드 (0) | 2020.05.08 |
| [신경망] RNN을 이용한 주식가격 예측 알고리즘 코드 (0) | 2020.05.07 |