[자연어처리] 문장 생성하기 (text generation)
2020. 5. 18. 16:21ㆍ노트/Python : 프로그래밍

# 텍스트 제너레이션
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
text="""과수원에 있는 배가 맛있다
그의 배는 많이 나왔다
가는 길에 배를 탔고 오는 길에도 배를 탔다\n"""
텍스트 인코딩
tok = Tokenizer()
tok.fit_on_texts([text])
vocSize=len(tok.word_index)+1
seqs = list()
for line in text.split("\n"):
encoded = tok.texts_to_sequences([line])[0]
for i in range(1, len(encoded)):
seq = encoded[:i+1]
seqs.append(seq)
maxLen=max(len(i) for i in seqs)
seqs=pad_sequences(seqs ,maxlen=maxLen, padding="pre")
seqs
>>>
array([[ 0, 0, 0, 0, 0, 0, 2, 3],
[ 0, 0, 0, 0, 0, 2, 3, 4],
[ 0, 0, 0, 0, 2, 3, 4, 5],
[ 0, 0, 0, 0, 0, 0, 6, 7],
[ 0, 0, 0, 0, 0, 6, 7, 8],
[ 0, 0, 0, 0, 6, 7, 8, 9],
[ 0, 0, 0, 0, 0, 0, 10, 11],
[ 0, 0, 0, 0, 0, 10, 11, 1],
[ 0, 0, 0, 0, 10, 11, 1, 12],
[ 0, 0, 0, 10, 11, 1, 12, 13],
[ 0, 0, 10, 11, 1, 12, 13, 14],
[ 0, 10, 11, 1, 12, 13, 14, 1],
[10, 11, 1, 12, 13, 14, 1, 15]])
seqs = np.array(seqs)
x = seqs[:,:-1]
x
>>>
array([[ 0, 0, 0, 0, 0, 0, 2],
[ 0, 0, 0, 0, 0, 2, 3],
[ 0, 0, 0, 0, 2, 3, 4],
[ 0, 0, 0, 0, 0, 0, 6],
[ 0, 0, 0, 0, 0, 6, 7],
[ 0, 0, 0, 0, 6, 7, 8],
[ 0, 0, 0, 0, 0, 0, 10],
[ 0, 0, 0, 0, 0, 10, 11],
[ 0, 0, 0, 0, 10, 11, 1],
[ 0, 0, 0, 10, 11, 1, 12],
[ 0, 0, 10, 11, 1, 12, 13],
[ 0, 10, 11, 1, 12, 13, 14],
[10, 11, 1, 12, 13, 14, 1]])
y = seqs[:, -1]
y = to_categorical(y, num_classes = vocSize)
y
>>>
array([[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]],
dtype=float32)
모델 생성
from keras.layers import SimpleRNN
from keras.models import Sequential, Model
# 모델 구성
model = Sequential()
model.add(Embedding(vocSize, 10, input_length= maxLen-1, ))
#입력차원, 출력차원, 8-1
model.add(SimpleRNN(32))
# 각 단어의 임베딩 벡터가 10차원
model.add(Dense(vocSize, activation="softmax"))
model.compile(loss="categorical_crossentropy", metrics = ["accuracy"], optimizer ="adam")
model.fit(x,y,epochs=200)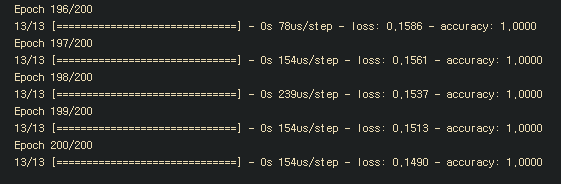
문장 생성
# 문장생성함수
def sentGen(model, tok, word, n): # 모델, 토큰나이저, 입력단어, 예측단어개수
sent = ""
word2=word
for _ in range(n): #3번 반복
encoded = tok.texts_to_sequences([word])[0] # "과수원에" <=> [2]
encoded = pad_sequences([encoded], maxlen = 7, padding="pre")
res = model.predict_classes(encoded)
for w , i in tok.word_index.items():
if i == res: # 예측단어와 인덱스가 동일한 단어를 의미함
break
word = word + " " + w
sent = sent + " " + w
sent = word2 + sent
return sent
>>>
print(sentGen(model, tok, "과수원에",3))
# 과수원에 뒤에 등장하는 3개의 단어 예측
>>> 과수원에 있는 배가 맛있다
<헌법 데이터로 문장 생성하기>
# text generation
from konlpy.corpus import kolaw # 헌법데이터
from konlpy.tag import Okt # 형태소 분석기
from nltk.tokenize import sent_tokenize
c= kolaw.open("constitution.txt").read()
c # len(18884)

텍스트 전처리
doc0=[" ".join( ["".join(w) for w , t in okt.pos(s)
if t not in ["Number", "Foreign"]
and w not in ["제", "조"] ] ) for s in sent_tokenize(c) ]
# 텍스트 제너레이션
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer()
tokenizer.fit_on_texts(doc0)
doc = [ tok for tok in tokenizer.texts_to_sequences(doc0) if len(tok) > 1 ] # 공백문자 제거를 위해
maxLen = max([len(x)-1 for x in doc] ) # 0번부터 시작하게 하려고
print(maxLen)
vocabSize = len(tokenizer.word_index)+1 #1164 + 1
print(vocabSize)
>>>
187
1165
텍스트 인코딩
from tensorflow.keras.utils import to_categorical
def genData(doc, maxLen, vocabSize):
for sent in doc:
inputs=[]
targets=[]
for i in range(1, len(sent)):
inputs.append(sent[0:i])
targets.append(sent[i])
y = to_categorical(targets, vocabSize)
inputSeq = pad_sequences(inputs, maxlen=maxLen)
yield(inputSeq,y)
# print("inputs:", inputs)
# print("-"*50)
# print("targets:", targets)
# print("-"*50)
def cf():
for i in range(3):
yield i*i
obj = cf()
for i in obj :
print(i)
for i , (x,y) in enumerate(genData(doc, maxLen, vocabSize)) :
print(i)
print("x", x.shape, "\n", x)
print("y", y.shape, "\n", y)
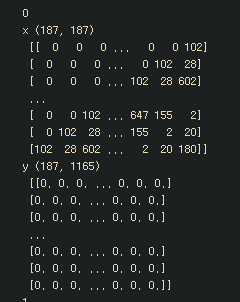
배열 합치기
import numpy as np
xdata = []
ydata = []
for (x,y) in genData(doc,maxLen, vocabSize):
xdata.append(x)
ydata.append(y)
xdata = np.concatenate(xdata)
ydata = np.concatenate(ydata)
모델 생성
from keras.layers import Input, Embedding, Dense , LSTM ,Dropout
from keras.models import Sequential
# 모델 작성
model = Sequential()
model.add(Embedding(vocabSize,100 , input_length = maxLen)) #1165, 100
model.add(LSTM(100, return_sequences = False ))
model.add(Dropout(0.5))
model.add(Dense(vocabSize, activation="softmax"))
model.compile(loss="categorical_crossentropy", optimizer ="rmsprop", metrics = ["accuracy"])
model.fit(xdata,ydata, epochs = 500, batch_size=800)
model.save("tentGen.hdf5") # 모델 저장 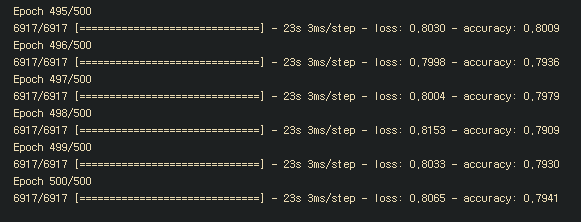
from keras.models import load_model
model=load_model("tentGen.hdf5") # 모델 불러오기
wordList="대한민국 의 국민 이 되는 요건 은 법률 로 정한 다 .".split()
wordList
>>> ['대한민국', '의', '국민', '이', '되는', '요건', '은', '법률', '로', '정한', '다', '.']
reverseWordMap = dict(map(reversed,tokenizer.word_index.items()))
x = pad_sequences( [[tokenizer.word_index[w] for w in wordList[:2] ]] , maxlen=maxLen)
p = model.predict(x)[0]
idx = np.flip(p.argsort(),0 ) # 내림차순 정렬
p[idx]
for i in idx[:10]:
print(reverseWordMap[i])
>>>
영토
주권
국민
자백
종류
경
모든
세입
근로
외국
문장생성하기
def predictWord(i, n):
x = pad_sequences([[tokenizer.word_index[w] for w in wordList[:i]]], maxlen = maxLen)
p = model.predict(x)[0]
idx = np.flip(np.argsort(p) , 0)
for j in idx[:n]:
print(" ".join(wordList[:i]), reverseWordMap[j], "(p={:4.2f}%)".format(100*p[j]))
predictWord(1,3) # "대한민국" 다음 단어? 3개 추천
print("="*30)
predictWord(2,3) # "대한민국 의" 다음 단어? 3개 추천
print("="*30)
predictWord(5,3) # "대한민국 의 국민 이 되는" 다음 단어? 3개 추천
>>>
대한민국 의 (p=47.58%)
대한민국 은 (p=41.26%)
대한민국 헌법 (p=2.23%)
==============================
대한민국 의 영토 (p=24.13%)
대한민국 의 주권 (p=20.84%)
대한민국 의 국민 (p=8.99%)
==============================
대한민국 의 국민 이 되는 요건 (p=95.52%)
대한민국 의 국민 이 되는 지방자치단체 (p=1.29%)
대한민국 의 국민 이 되는 대한민국 (p=0.88%)
'노트 > Python : 프로그래밍' 카테고리의 다른 글
| [머신러닝] 결정트리와 랜덤포레스트를 이용한 분류 기법 (0) | 2020.05.19 |
|---|---|
| [자연어처리] LSTM을 이용한 챗봇(chatbot) 만들기 (0) | 2020.05.18 |
| [자연어처리] word2vec 로 워드임베딩 하기 (0) | 2020.05.18 |
| [자연어처리] 번역기 프로그램 만들기 (0) | 2020.05.14 |
| [자연어처리] 케라스로 단어사전 만들기 (0) | 2020.05.08 |