[자연어처리] 케라스로 단어사전 만들기
2020. 5. 8. 14:45ㆍ노트/Python : 프로그래밍

단어 토큰화
from keras.preprocessing.text import Tokenizer
tok = Tokenizer()
text = "Regret for wasted time is more wasted time"
tok.fit_on_texts([text]) # 사전을 생성
#[text] : 단어 단위 토큰화
#text : 문자 단위 토큰화
print(tok.word_index)
test = "Regret for wasted time is more wasted hour"
seq = tok.texts_to_sequences([test])
# 사전에 test에 저장된 단어가 있는지 확인
from keras.preprocessing.sequence import pad_sequences
# pad_sequences: 샘플의 길이를 동일하게 해주는 함수
pad_sequences([[1,2,3],
[2,3,4,5],
[6,7]], maxlen = 3, padding ="pre")
워드 임베딩: 문장 내의 단어들을 밀집 벡터로 만드는 작업
원핫벡터(고차언,희소벡터, 기억장소낭비)
밀집벡터(저차원, 실수값)
ex) 원핫벡터: 00000,.....000(tiger)
ex) 밀집벡터:[0.1 -1.5 1.9 2.4] (tiger)
ex) text = [[0,1,2,3],[3,4,1,5]]
=> Embedding(6,2,4)
=> 0 -> [1.3, 1.5], 1 ->[2.5, 4.1],...
6: 단어갯수, 2: 벡터크기, 4: 시퀀스 길이
모델 생성
# functional API
from keras.layers import Input ,Dense , LSTM
from keras.models import Model
# 일반 신경망 모델 생성
inp = Input(shape=(10,)) # 10개입력, 입력층
h1 = Dense(32, activation='relu')(inp)
h2 = Dense(16, activation='relu')(h1)
outp = Dense(1, activation='sigmoid')(h2)
model = Model(inputs= inp, outputs = outp)
# LSTM 모델 생성
inp = Input(shape=(50,1))
h1 = LSTM(10)(inp)
h2 = Dense(10, activation="relu")(h1)
outp = Dense(1, activation="sigmoid")(h2)
model = Model(inputs=inp, outputs=outp)
MLP 신경망 텍스트 분류
# MLP : Multi Layer Perceptron
# MLP로 텍스트 분류 작업
from keras.preprocessing.text import Tokenizer
import numpy as np
texts=["먹고 싶은 사과", "먹고 싶은 바나나","길고 노란 바나나 바나나","저는 과일이 좋아요"]
#토큰화
tok = Tokenizer()
tok.fit_on_texts(texts)
print(tok.word_index)
>>> {'바나나': 1, '먹고': 2, '싶은': 3, '사과': 4, '길고': 5, '노란': 6, '저는': 7, '과일이': 8, '좋아요': 9}
texts_to_matrix()
tok.texts_to_matrix(texts, mode= "count")
# DTM mode를 count를 하면 생성됌
>>>
array([[0., 0., 1., 1., 1., 0., 0., 0., 0., 0.],
[0., 1., 1., 1., 0., 0., 0., 0., 0., 0.],
[0., 2., 0., 0., 0., 1., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 1., 1.]])
tok.texts_to_matrix(texts, mode= "tfidf")
# 먹고싶은 사과 1.09861229 에서 사과가 가장 중요한 단어라고 인식할 수 있음
>>>
array([[0. , 0. , 0.84729786, 0.84729786, 1.09861229,
0. , 0. , 0. , 0. , 0. ],
[0. , 0.84729786, 0.84729786, 0.84729786, 0. ,
0. , 0. , 0. , 0. , 0. ],
[0. , 1.43459998, 0. , 0. , 0. ,
1.09861229, 1.09861229, 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. ,
0. , 0. , 1.09861229, 1.09861229, 1.09861229]])
tok.texts_to_matrix(texts, mode= "binary") # 단어 생성 유무
>>>
array([[0., 0., 1., 1., 1., 0., 0., 0., 0., 0.],
[0., 1., 1., 1., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 1., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 1., 1.]])
tok.texts_to_matrix(texts, mode= "freq") # 문장단위 비율
>>>
array([[0. , 0. , 0.33333333, 0.33333333, 0.33333333,
0. , 0. , 0. , 0. , 0. ],
[0. , 0.33333333, 0.33333333, 0.33333333, 0. ,
0. , 0. , 0. , 0. , 0. ],
[0. , 0.5 , 0. , 0. , 0. ,
0.25 , 0.25 , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0.33333333, 0.33333333, 0.33333333]])
연습문제
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
from keras.utils import to_categorical
import matplotlib.pyplot as plt
newsData= fetch_20newsgroups(subset = "train") #test, all 지정 가능
print(newsData.keys())
>>> dict_keys(['data', 'filenames', 'target_names', 'target', 'DESCR'])
len(newsData.data)
print(newsData.target)
>>> [7 4 4 ... 3 1 8]
print(newsData.target[10]) #11314
print(newsData.target_names[10])
>>>
8
rec.sport.hockey
df=pd.DataFrame(newsData.data, columns=['email'])
#df['target']=newsData.target
df['target']=pd.Series(newsData.target)
df['email'].nunique() #11314개 샘플
df['target'].nunique() #20가지 주제
#주제별 샘플의 개수 확인
df['target'].value_counts().plot(kind='bar')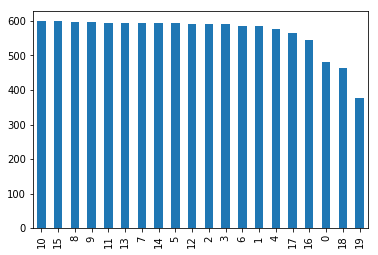
df.groupby('target').size()
>>>
target
0 480
1 584
2 591
3 590
4 578
5 593
6 585
7 594
8 598
9 597
10 600
11 595
12 591
13 594
14 593
15 599
16 546
17 564
18 465
19 377
dtype: int64pad_sequences([[1,2,3],
[2,3,4,5],
[6,7]], maxlen = 3, padding ="pre")
trainEmail=df['email']
trainLabel=df['target']
testEmail=newsDataTest.data #테스트 데이터 본문
testLabel=newsDataTest.target
Train Test 데이터 생성
def preData(trainData,testData,mode): #preprocessing
tok=Tokenizer(num_words=10000) #빈도수가 가장 높은 상위 10000개의 단어를 사용
tok.fit_on_texts(trainData)
xTrain=tok.texts_to_matrix(trainData,mode=mode)
xTest=tok.texts_to_matrix(testData,mode=mode)
return xTrain, xTest, tok.index_word
xTrain, xTest, index_word=preData(trainEmail, testEmail, 'binary') yTrain=to_categorical(trainLabel,20)
yTest=to_categorical(testLabel,20)
#MLP 기반 텍스트 분류 모델
from keras.layers import Dropout
from keras.models import Sequential
def fitEval(xTrain, yTrain, xTest, yTest): # fit & evaluate 수행함수
model = Sequential()
model.add(Dense(256, input_shape=(10000,), activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(128, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(20, activation="softmax"))
model.compile(loss="categorical_crossentropy", optimizer = "adam", metrics=["accuracy"])
model.fit(xTrain, yTrain, batch_size = 128, epochs = 5, validation_split=0.1, verbose = 1 )
score = model.evaluate(xTest, yTest, batch_size=128)
return score[1]
score = fitEval(xTrain, yTrain, xTest, yTest)

xTrain, xTest,_ = preData(trainEmail, testEmail, "binary")
score = fitEval(xTrain,yTrain,xTest,yTest)
print("정확도:", score)
>>>
Train on 10182 samples, validate on 1132 samples
Epoch 1/5
10182/10182 [==============================] - 4s 412us/step - loss: 2.2904 - accuracy: 0.3293 - val_loss: 0.9782 - val_accuracy: 0.8198
Epoch 2/5
10182/10182 [==============================] - 4s 382us/step - loss: 0.8610 - accuracy: 0.7620 - val_loss: 0.4503 - val_accuracy: 0.9055
Epoch 3/5
10182/10182 [==============================] - 4s 382us/step - loss: 0.4319 - accuracy: 0.8879 - val_loss: 0.3465 - val_accuracy: 0.9064
Epoch 4/5
10182/10182 [==============================] - 4s 383us/step - loss: 0.2574 - accuracy: 0.9353 - val_loss: 0.3045 - val_accuracy: 0.9072
Epoch 5/5
10182/10182 [==============================] - 4s 383us/step - loss: 0.1639 - accuracy: 0.9603 - val_loss: 0.2937 - val_accuracy: 0.9134
7532/7532 [==============================] - 1s 130us/step
정확도: 0.8284652233123779'노트 > Python : 프로그래밍' 카테고리의 다른 글
| [자연어처리] word2vec 로 워드임베딩 하기 (0) | 2020.05.18 |
|---|---|
| [자연어처리] 번역기 프로그램 만들기 (0) | 2020.05.14 |
| [신경망] LSTM을 이용한 "나비야" 작곡하기 코드 (0) | 2020.05.08 |
| [신경망] RNN을 이용한 주식가격 예측 알고리즘 코드 (0) | 2020.05.07 |
| [신경망] RNN을 이용한 단어 번역 알고리즘 코드 (0) | 2020.05.01 |