2020. 4. 27. 10:58ㆍ노트/Python : 프로그래밍

데이터 다운로드
https://www.kaggle.com/c/dogs-vs-cats/data
Dogs vs. Cats
Create an algorithm to distinguish dogs from cats
www.kaggle.com
★대용량주의
학습데이터 준비

import pandas as pd
import numpy as np
from keras.preprocessing.image import *
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import random
import os
path = "C:\\Users\\student\\Desktop\\DY\\★ 데이터\\106. cnn_dataset\\"
# 데이터 형상 관련 상수 정의
IMAGE_WIDTH=128
IMAGE_HEIGHT=128
IMAGE_SIZE=(IMAGE_WIDTH, IMAGE_HEIGHT)
IMAGE_CHANNEL=3
# 학습 데이터 준비
filenames = os.listdir(path+"train")
categories=[]
for filename in filenames:
category=filename.split(".")[0]
if category =="dog":
categories.append(1)
else:
categories.append(0)
df=pd.DataFrame(
{"filename":filenames,
"category":categories}
)
df* 고양이 = 0, 개 = 1로 정답 레이블 (category) 생성
%matplotlib notebook
df['category'].value_counts().plot.bar()
%matplotlib notebook
sample = random.choice(filenames)
image = load_img(path+"train\\"+sample)
plt.imshow(image)
모델 생성
* 배치정규화(Batch Normalization):
신경망 입력 데이터를 평균 : 0 , 분산: 1로 정규화를 해서 학습이 잘 이루어지도록 하는 방법
강아지 - 레이어1 - 레이어2 - 레이어3 - FullyConnected - 분류결과
(Conv) ... ... (Flatten)
(BatchNorm) ... ... (Dense)
(Pool) ... ... (BatchNorm)
(DropOut) ... ... (Dropout)
from keras.models import Sequential
from keras.layers import * # 레이어 1
model = Sequential()
model.add(Conv2D(32, (3,3), activation="relu", input_shape=(IMAGE_HEIGHT, IMAGE_WIDTH , IMAGE_CHANNEL)))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
# 레이어 2
model.add(Conv2D(64, (3,3), activation="relu"))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
# 레이어3
model.add(Conv2D(128, (3,3), activation="relu"))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
# Fully Connected
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(2,activation="softmax"))# 모델 실행 옵션
model.compile(loss="categorical_crossentropy", optimizer="rmsprop", metrics=['accuracy'])
model.summary()
# reduceLROnPlateau
# : callback 함수의 일종, learning rate가 더이상 업데이트가 되지 않으면, 학습을 중단하여라
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
earlystop = EarlyStopping(patience=10)
learning_rate_reduction=ReduceLROnPlateau(
monitor= "val_accuracy",
patience = 2,
factor = 0.5,
min_lr=0.0001,
verbose=1)
callbacks = [earlystop, learning_rate_reduction]- reduceLRONplateau :
plateau 는 정체기란 뜻으로
모델의 정확도가 향상되지 않는 경우 ㅡ learning rate (lr) 을 줄여주는 클래스
# 이미지 제너레이터에서 class_mode = "categorical"로 지정하기 위해 컬럼 카테고리를 스트링으로 변경함.
df['category']=df['category'].replace({0:'cat',1:"dog"})
test , train 데이터 분리
train_df, validate_df = train_test_split(df , test_size=0.2, random_state= 42)
train_df=train_df.reset_index(drop=True)
validate_df=validate_df.reset_index(drop=True)
train_df['category'].value_counts()
>>>
dog 10015
cat 9985
Name: category, dtype: int64
validate_df['category'].value_counts()
>>>
cat 2515
dog 2485
Name: category, dtype: int64
트레이닝 데이터의 제너레이터 설정
total_train=train_df.shape[0]
total_validate=validate_df.shape[0]
batch_size=15
# 트레이닝 데이터의 제너레이터 설정
train_datagen=ImageDataGenerator(
rotation_range=15,
rescale=1./255,
shear_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1)
train_generator=train_datagen.flow_from_dataframe(
train_df,
path+"train",
x_col = "filename",
y_col = "category",
target_size = IMAGE_SIZE,
class_mode = "categorical",
batch_size = batch_size )
validate_datagen=ImageDataGenerator(rescale=1./255)
# 검증이미지니까, 사진 그대로 쓰겠다.
validation_generator=validate_datagen.flow_from_dataframe(
validate_df,
path+"train",
x_col= "filename",
y_col= "category",
target_size = IMAGE_SIZE,
class_mode = "categorical",
batch_size = batch_size )
샘플데이터 확인
example_df=train_df.sample(n=1).reset_index(drop=True)
example_df
example_generator = train_datagen.flow_from_dataframe(
example_df,
path+"train",
x_col = "filename",
y_col = "category",
target_size = IMAGE_SIZE,
class_mode = "categorical")plt.figure(figsize=(10,10))
for i in range(0,15):
plt.subplot(5,3,i+1)
for xBatch, yBatch in example_generator:
image = xBatch[0]
plt.imshow(image)
break
plt.tight_layout()
plt.show()
트레이닝
epochs = 3
history = model.fit_generator(
train_generator,
epochs = epochs,
steps_per_epoch = total_train//batch_size ,
validation_data= validation_generator,
validation_steps = total_validate//batch_size,
callbacks = callbacks,
)
# 모델 저장
model.save_weights("model.h5")
트레이닝 모델 히스토리 시각화
historyDict=history.history
acc=history.history['accuracy']
val_acc=history.history['val_accuracy']
loss=history.history['loss']
val_loss=history.history['val_loss']
%matplotlib notebook
epo = range(1, len(acc)+1)
plt.plot(epo, loss, 'bo', label="Traing loss")
plt.plot(epo, val_loss, 'b', label="Val loss")
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()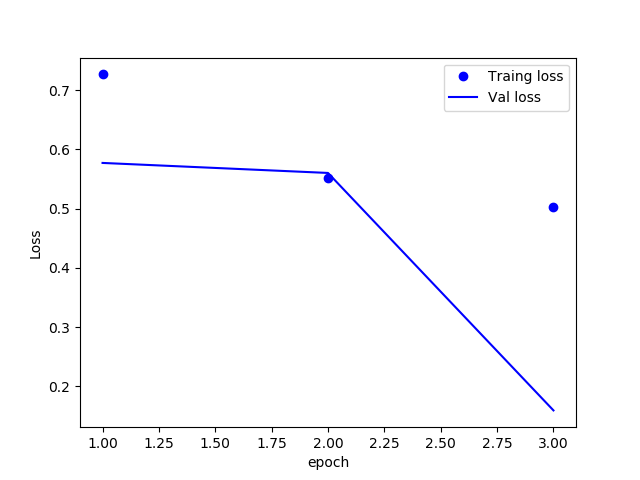
%matplotlib notebook
plt.plot(epo, acc, 'ro', label="Traing accuracy")
plt.plot(epo, val_acc, 'r', label="Val accuracy")
plt.xlabel("epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
테스트
# 테스트 데이터 준비
filenames = os.listdir(path+"test1")
test_df=pd.DataFrame( {"filename":filenames} )
test_df
nbsamples=test_df.shape[0]test_datagen=ImageDataGenerator(rescale=1./255)
# 테스트 이미지니까, 사진 그대로 씀
test_generator=test_datagen.flow_from_dataframe(
test_df,
path+"test1",
x_col= "filename",
y_col= None,
target_size = IMAGE_SIZE,
class_mode = None,
batch_size = batch_size,
shuffle = False)# 3. 예측
predict=model.predict_generator(test_generator,
steps=nbsamples/batch_size,
callbacks=callbacks)
test_df['category']=np.argmax(predict, axis=1)
테스트 샘플 랜덤으로 추출해서 확인
test_df['category']=test_df['category'].replace({0:'cat',1:"dog"})
ex_df=test_df.sample(n=1).reset_index(drop=True)
ex_df

ex_generator = test_datagen.flow_from_dataframe(
ex_df,
path+"test1",
x_col = "filename",
y_col = None,
target_size = IMAGE_SIZE,
class_mode = None)test_sample=list(ex_df.filename)
sample = ""
for test in test_sample:
sample += test
image = load_img(path+"test1\\"+sample)
plt.figure(figsize=(8,8))
plt.imshow(image)
plt.tight_layout()
plt.show()
제출할 양식에 맞게 수정
sampleSubmission=pd.read_csv(path+"sampleSubmission.csv", dtype="object")
sampleSubmission
index=[]
for filename in test_df.filename:
li=filename.split(".")[0]
index.append(li)
test_df["id"]=index
final=test_df.merge(sampleSubmission)[['id','category']]
final['id']=final['id'].astype("int64")
final=final.sort_values("id")
final.rename({'category':"label"},axis='columns').to_csv("Submission.csv", index=False)
'노트 > Python : 프로그래밍' 카테고리의 다른 글
| [케라스] Fashion-Mnist 기반 CNN모델 코드 (0) | 2020.04.28 |
|---|---|
| [파이썬기초] 파이썬 함수 활용 모음 (0) | 2020.04.27 |
| [케라스 오류 해결] TypeError: The added layer must be an instance of class Layer (0) | 2020.04.24 |
| [케라스] 이미지 증식하기 코드 (1) | 2020.04.24 |
| [신경망] MNIST 데이터를 이용한 CNN모델 코드 (0) | 2020.04.23 |