2021. 4. 20. 17:50ㆍ레퍼런스/Tech : 기술
A 2019 Guide to Human Pose Estimation | by Derrick Mwiti | Heartbeat (fritz.ai)
A 2019 Guide to Human Pose Estimation
Examining popular and current approaches
heartbeat.fritz.ai

A 2019 Guide to Human Pose Estimation
사람 포즈 추정은 이미지 속의 포즈를 추론하는 과정을 의미합니다. 특히, 이미지나 비디오의 사람의 관절 위치를 예측하는 것을 수반합니다. 이 문제는 보통 신체 관철의 지역화(localization)라고 언급됩니다. 또한 포즈 추정은 싱글 포즈 추정, 다수 사람이 있는 이미지의 포즈 추정, 붐비는 장소에서의 포즈 추정, 비디오에서의 포즈 추정 등 다양한 하위 태스크를 가지고 있다는 것을 아는 것은 중요합니다.
포즈 추정은 3D나 2D로 수행될 수 있습니다. 몇몇의 포즈 추정의 애플리케이션은 다음을 포함합니다. :
우리가 강조할 이 연구에서 사용된 몇몇 접근들은 bottom-up 방식과 top-down 방식 입니다. 특히, bottom-up 방식에서, 고해상도에서 저해상도로 과정이 수행됩니다. 반면, top-down 방식에서는 저해상도에서 고해상도로 과정이 수행됩니다.
top-down 접근은 물체 탐지기(object detector) 를 사용하여, 개별 사람 인스턴스를 식별하고(identifying) 지역화(localizing)하면서 시작합니다. 그리고 나서, 한 사람의 포즈를 추정합니다. bottom-up 방식은 확인되지 않은(identity-free) 의미론적 실체(semantic entities)를 지역화한다음, 사람 인스턴스로 그룹화하는 것으로 시작합니다.
이제, 사람 포즈 추정 문제를 해결하고자 시도했던 몇몇 연구들을 확인할 것입니다.
- DeepPose: Human Pose Estimation via Deep Neural Networks
- Efficient Object Localization Using Convolutional Networks
- Human Pose Estimation with Iterative Error Feedback
- Stacked Hourglass Networks for Human Pose Estimation
- Convolutional Pose Machines
- DeepCut: Joint Subset Partition and Labeling for Multi-Person Pose Estimation
- Simple Baselines for Human Pose Estimation and Tracking
- RMPE: Regional Multi-Person Pose Estimation
- OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity
- Human Pose Estimation for Real-World Corwded Scenarios
- DensePose: Dense Human Pose Estimation In The Wild
- PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
DeepPose: Human Pose Estimation via DeepNeural Networs (CVPR, 2014)
이 논문은 이 ML과제를 다루기 위해 깊은 신경망(DNNs)을 사용하는 것을 제안했습니다. 이 논문의 저자는 Google의 Alexander Toshev 와 Christian Szegedy 입니다. 포즈 추정 자체의 공식은 관절에 대한 DNN 기반 회귀입니다. 저자는 MPⅡ, LSP 와 FLIC데이터셋 과 같은 표준 벤치마크에 대한 최신의 결과를 달성했습니다. 또한 반복적인 중간 감독으로 멀티 스테이지 아키텍쳐를 결합하여 훈련하는 영향에 대해서도 분석하였습니다.
DeepPose: Human Pose Estimation via Deep Neural Networks
We propose a method for human pose estimation based on Deep Neural Networks (DNNs). The pose estimation is formulated as a DNN-based regression problem towards body joints. We present a cascade of such DNN regressors which results in high precision pose es
arxiv.org
DNN은 모든 관절의 문맥을 포착하는 것이 가능하며, 그래프적 모델의 사용이 필요하지 않습니다. 아래에서 볼 수 있듯, 네트워크는 7개의 층으로 구성됩니다. Pooling layer, convolution layer, fully-connected layer는 이 레이어의 일부를 구성합니다.
convolution layer와 fully-connected layer는 학습가능한 파라미터를 가진 유일한 층입니다. 둘다 선형 변환에 이어 교정된 선형 유닛을 포함합니다. 네트워크의 입력 이미지 크기는 220 x 220 이고, learning rate는 0.0005입니다. fully-connected layer에 대한 드롭아웃 정규화는 0.6으로 설정됐습니다. 이 모델에 사용된 몇몇 데이터셋은 Frames Labeled In Cinema (FLIC) 와 Leeds Sports Dataset 입니다.

아래 그림은 Percentage of Correct Parts (PCP) 평가지표에 대한 모델의 성능을 보여줍니다.


Efficient Object Localization Using Convolutional Networks (2015)
이 논문은 단안의(monocular) RGB 이미지의 신체 관절의 위치를 예측하는 ConvNet 아키텍쳐를 제안합니다. 이 논문의 저자는 New York 대학교 소속입니다. 이 모델을 사용하면 풀링을 증가시켜 계산 효율성을 향상시킬 수 있습니다.
Efficient Object Localization Using Convolutional Networks
Recent state-of-the-art performance on human-body pose estimation has been achieved with Deep Convolutional Networks (ConvNets). Traditional ConvNet architectures include pooling and sub-sampling layers which reduce computational requirements, introduce in
arxiv.org
이 네트워크는 처음에 신체 부분의 지역화를 수행하고, 저 해상도의 픽셀 당 히트맵을 출력합니다. 이 히트맵은 이미지 의 각 공간 위치에서 관절이 나타날 확률을 보여줍니다.

이 논문은 또한 지역화(localization) 정확도를 향상시키기 위하여 히트맵 회귀 모델의 은닉층으로 부터 feature들을 사용하는 네트워크를 소개합니다. 이 모델은 멀티-해상도 ConvNet 아키텍처를 사용하고, 겹치는 문맥을 가진 슬라이딩 윈도우 탐지기를 사용하여 조악한 히트맵 출력값을 생성합니다. 슬라이딩 윈도우는 보통 고정된 높이와 너비를 가진 직사각형 박스입니다. 이 박스는 이미지를 가로질러 슬라이드합니다. 박스가 슬라이드 할 때, 분류기는 해당 섹션에 현재 작업에 관심있는 개체가 있는지 여부를 식별하려고 합니다.
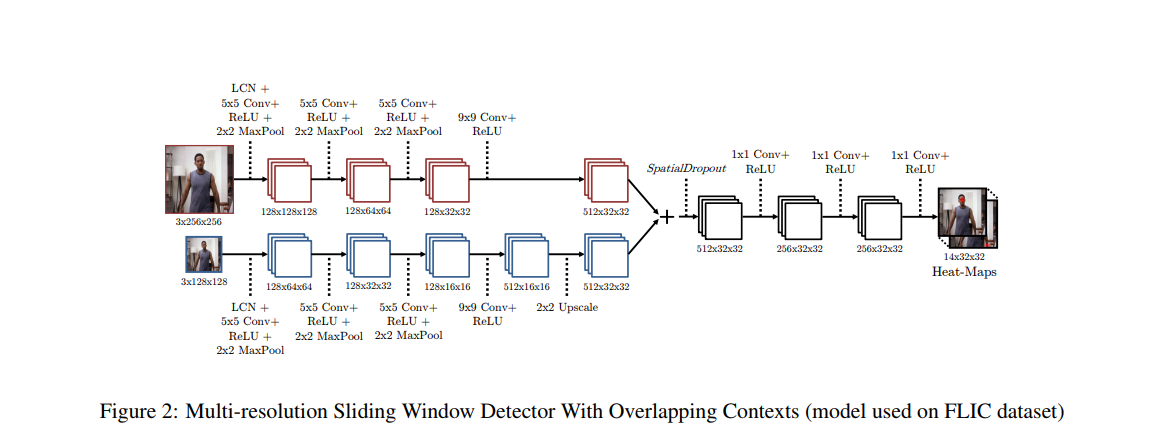
아래의 그림은 이 논문에서 제안된 전체 모델의 아키텍쳐를 보여줍니다. 이 아키텍쳐는 Torch7로 실행이 되고, FLIC와 MPⅡ-사람 포즈 데이터셋을 사용하여 평가되었습니다.

이 모델의 성능은 FLIC 데이터셋에 대해 표준 PCK (Percentage of Correct Keypoints) 척도를 사용하고, MPⅡ 데이터셋에 대해 PCKh 척도를 사용하여 평가되었습니다.


Human Pose Estimation with Iterative Error Feedback (2016)
이 논문은 계층적 feature 추출기의 표현력을 입력과 출력 공간 둘 다 포함하도록 확장하는 프레임워크를 제안했습니다. top-down 피드백을 도입함으로써 이를 수행합니다. 이 논문의 저자는 UC Berkeley 소속입니다.
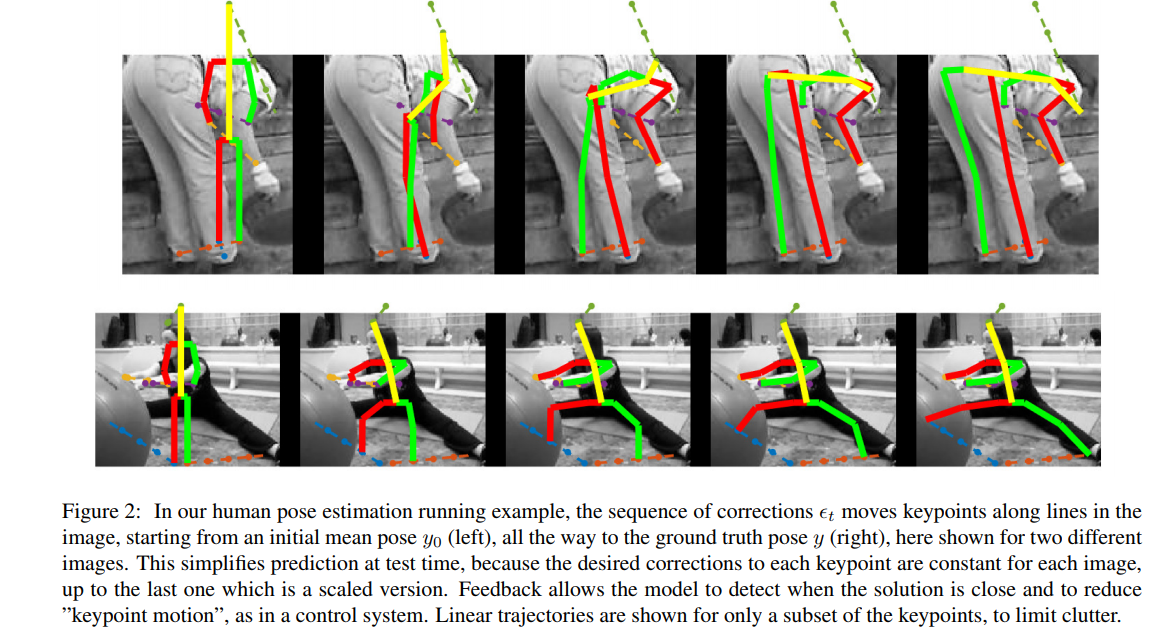
출력 값은 한번에 예측되지 않습니다. 하지만, 오류 예측을 피드백하는 자가 수정 모델이 사용됩니다. 저자는 이 과정을 반복적인 에러 피드백 (Iterative Error Feedback (IEF)) 라고 불렀습니다. 이 모델은 MPⅡ 와 LSP 벤치마크에 대해 관절 포즈 추정에 대한 좋은 결과를 생산했습니다.
Human Pose Estimation with Iterative Error Feedback
Hierarchical feature extractors such as Convolutional Networks (ConvNets) have achieved impressive performance on a variety of classification tasks using purely feedforward processing. Feedforward architectures can learn rich representations of the input s
arxiv.org
아래의 그림은 2D 사람 포즈 추정에 대한 반복적인 에러 피드백 실행을 보여줍니다. 왼쪽 패널은 입력이미지 I 와 초기 키포인트 추정값 Y0를 보여줍니다. 여기서 3가지 키포인트는 오른쪽 손목 (녹색), 왼쪽 손목 (파란색), 머리 꼭대기 (빨간색)에 대응합니다. 이 아키텍쳐의 함수 f는 합성곱 신경망으로 모델링됩니다. 함수 g는 각 2D 키포인트 위치를 가우시안 히트맵 채널로 변환합니다.
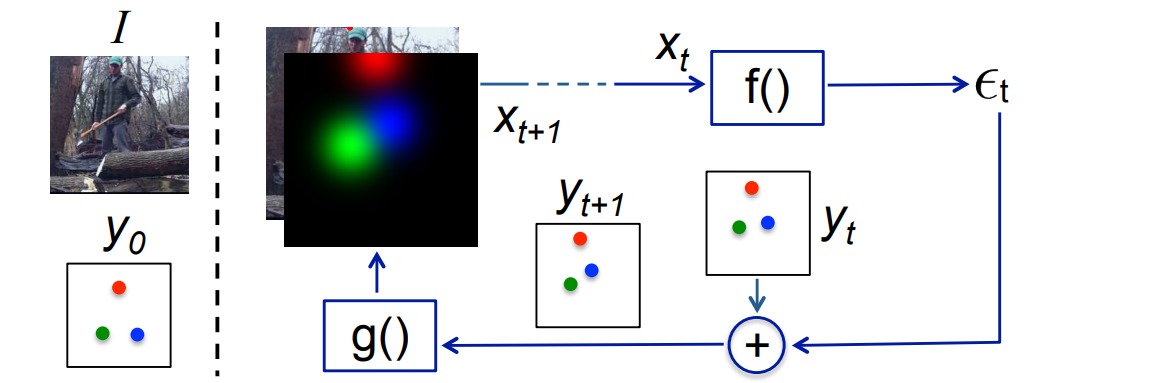

이 모델은 왼쪽의 수학적 등식을 사용하여 시각화될 수 있습니다.
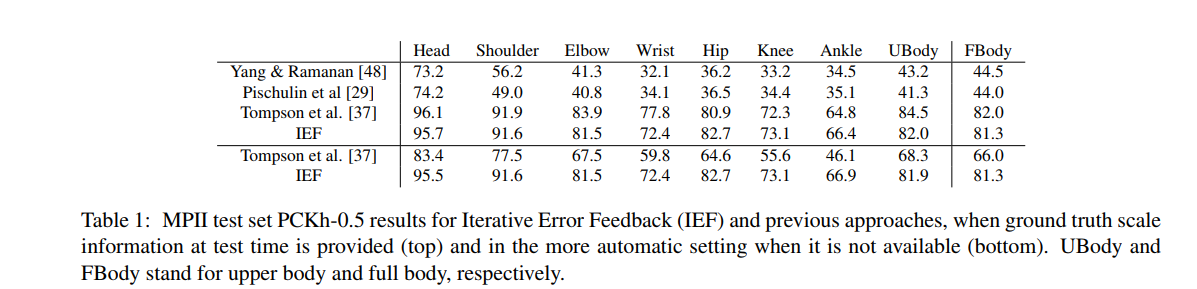
아래의 테이블은 이 모델의 성능을 나타냅니다.
Stacked Hourglass Networks for Human Pose Estimation (2016)
이 논문은 반복되는 bottom-up과 top-down 과정이 중간 감독과 함께 그들이 제안하는 네트워크의 성능을 향상시킨다고 주장한다. 이 네트워크는 "겹겹이 쌓인 모래시계 (stacked hourglass)"라고 언급되는데, 마지막 예측값을 생성하기 위해한 투표(polling)와 표본추출(upsampling)의 연속적인 과정 때문이다. 이 논문의 저자는 Michigan 대학교 소속이다.
Stacked Hourglass Networks for Human Pose Estimation
This work introduces a novel convolutional network architecture for the task of human pose estimation. Features are processed across all scales and consolidated to best capture the various spatial relationships associated with the body. We show how repeate
arxiv.org
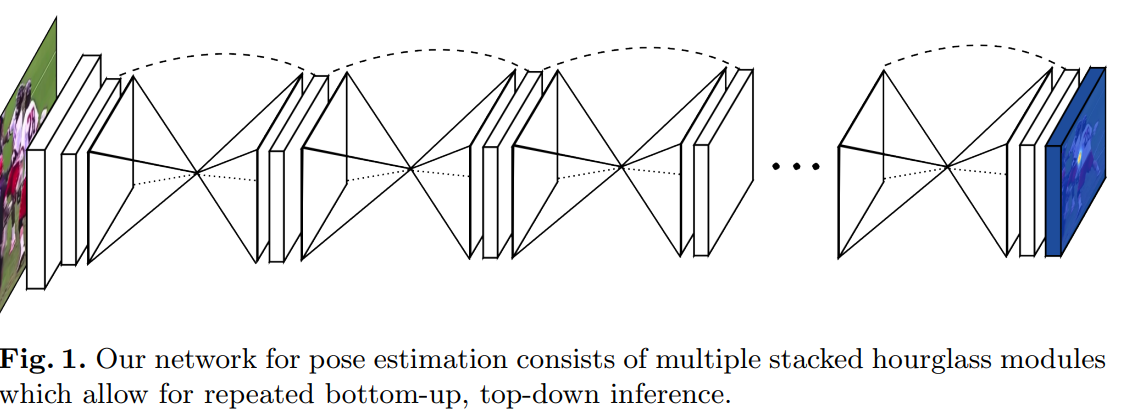
이 네트워크는 FLIC와 MPⅡ 사람 포즈 벤치마크를 이용하여 테스트되었다. 모든 관절들에 대해 MPⅡ의 정확도가 평균적으로 2% 이상 향상되었고, 발목과 무릎과 같은 다른 관절들에 대해서는 대략 4-5% 정도 정확도가 향상되었다.

모래시계 구조는 모든 규모에서 정보를 포착하기 위해 디자인되었다. 이 네트워크는 픽셀 단위의 예측값을 출력한다. 네트워크의 설정은 피쳐 가공에 사용되는 convolution layer와 max-pooling layer가 있다. 이 네트워크는 각 픽셀 수준에서 특정 관절이 나타날지를 예측하는 히트맵을 출력한다.

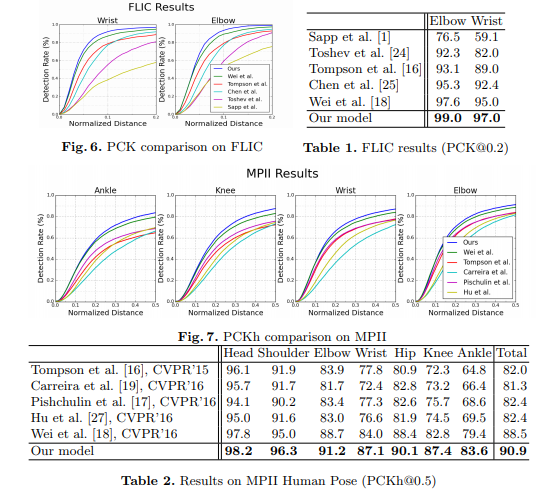
아래의 그림은 다양한 신체 부분에 대한 모델 성능을 보여준다.
Convolutional Pose Machines (2016)
이 논문은 관절이 있는 포즈 추정을 위한 합성곱 포즈 머신(Convolutional Pose Machines) (CPMs)을 소개합니다. CPMs은 각 부분의 위치에 대한 2D 신뢰도 맵을 만들어 내는 합성곱 네트워크의 시퀀스로 구성되어있습니다. 이 논문은 Carnegie Mellon 대학의 Robotics Institute 소속 입니다.
Convolutional Pose Machines
Pose Machines provide a sequential prediction framework for learning rich implicit spatial models. In this work we show a systematic design for how convolutional networks can be incorporated into the pose machine framework for learning image features and i
arxiv.org
CPM의 모든 단계에서, 각 이미지 feature와 이전 단계에서 생산되는 신뢰도 맵은 입력값으로 사용됩니다.

네트워크는 합성곱 아키텍쳐의 순차적인 구성을 통해 암묵적 공간 모델을 학습합니다. 또한, 구조화된 예측 작업을 위한 이미지 features들과 이미지에 의존적인 공간 모델을 학습하기 위해, 이러한 아키텍쳐를 설계하고 훈련하는 체계적인 접근 방식을 도입합니다. 이는 그래픽 모델 스타일 추론을 사용할 필요가 없습니다.
이 네트워크는 MPⅡ, LSP, 그리고 FLIC 데이터셋으로 테스트되었습니다.

모델의 PCKh-0.5 점수는 87.95% 라는 최신의 결과를 달성하였고, PCKh0.5 점수는 발목에 대해 78.28% 를 달성했습니다. Caffe를 사용하여 실행되었고, 코드는 오픈 소스화되었습니다.

DeepCut: Joint Subset Partition and Labeling for Multi-Person Pose Estimation (CVPR 2016)
이 논문은 다수 사람들이 있는 이미지에서 포즈를 탐지하는 방법을 제안합니다. 이 모델은 이미지에서 사람의 수를 탐지한 다음, 각 이미지에서 관절의 위치를 예측합니다. 이 논문은 Max Planck Institute와 Stanford 대학교에서 연구되었습니다.
DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation
This paper considers the task of articulated human pose estimation of multiple people in real world images. We propose an approach that jointly solves the tasks of detection and pose estimation: it infers the number of persons in a scene, identifies occlud
arxiv.org

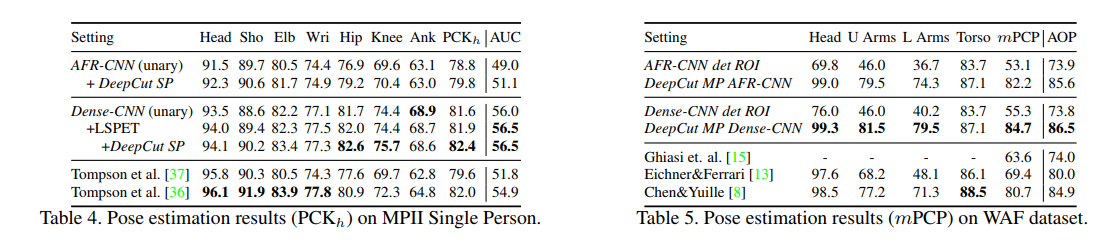
강한 부분 탐지기를 얻기 위해서, 저자는 작업에 FastRCN을 적용했습니다. 그들은 제안 생성(proposal generation)과 탐지 영역 크기(detection region size)라는 두가지 방식으로 이를 바꿨습니다. 다양한 신체부분을 예측하는 이 모델의 성능은 아래에서 볼 수 있습니다.
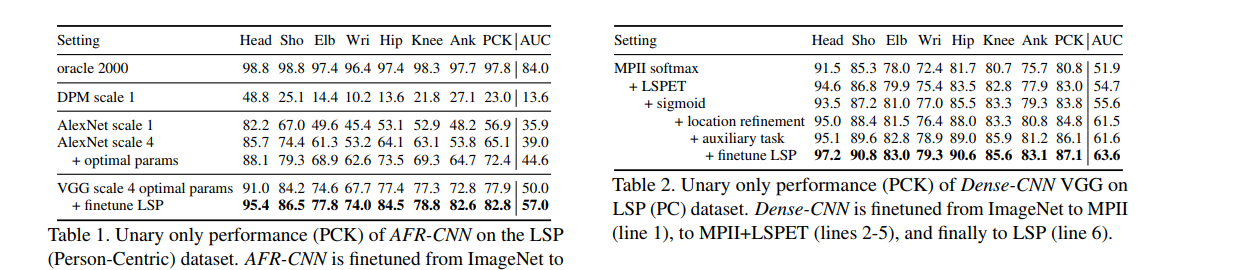
신체 부분 탐지를 위해 제안서(proposal)를 사용하는 것은 차선책이 될 수 있으므로, 저자는 stride가 32px인 fully-convolutional VGG를 사용했으며, 이 stride를 8px로 줄였습니다. 그리고 나서, 이미지 입력값을 340 px의 스탠딩 높이로 확장하여 최상의 결과를 얻었습니다.
손실 함수에 대해서, 처음에는 다른 신체 부분의 확률값을 출력하는 소프트맥스 함수를 시도했습니다. 이후에는 출력값 뉴런과 크로스 엔트로피 손실에 대해서 시그모이드 활성화 함수를 실행하였습니다. 마지막으로, 그들은 소프트맥스 손실 함수 보다 시그모이드 활성화 함수가 더 나은 결과를 얻는다는 것을 발견했습니다. 이 모델은 Leeds Sports Poses (LSP) 와 LSP Extended (LSPET) , 그리고 MPⅡ 사람 포즈 데이터에 대해서 학습되고 평가되었습니다.

Simple Baselines for Human Pose Estimation and Tracking (EECV, 2018)
이 논문의 포즈 추정 솔루션은 ResNet을 추가한 탈컨볼루젼 층(deconvolutional layers)에 기반했습니다. 이 모델은 COCO test-dev split 데이터에 대해 73.7의 mAP를 달성했습니다. 이 포즈 추적 모델은 mAP 점수가 74.6을, MOTA (Multiple Object Tracking Accuracy) 점수가 57.8을 달성했습니다. 이 논문의 저자는 Microsoft Research Asia 와 중국의 Electronic Science and Technology 대학 소속입니다.
Simple Baselines for Human Pose Estimation and Tracking
There has been significant progress on pose estimation and increasing interests on pose tracking in recent years. At the same time, the overall algorithm and system complexity increases as well, making the algorithm analysis and comparison more difficult.
arxiv.org
이 네트워크에서 사용된 방법은 몇몇 탈컨볼루젼 층(deconvolutional layers)을 ResNet 구조의 마지막 컨볼루전 단계 이후에 추가합니다. 이 구조는 깊고- 저-해상도 이미지로 부터 히트맵을 생성하는 것을 매우 쉽게 만듭니다. 배치 정규화와 ReLU 활성화 함수와 함께 3가지 탈컨볼루젼 층 (deconvolutional layers) 가 디폴트 값으로 사용됩니다.
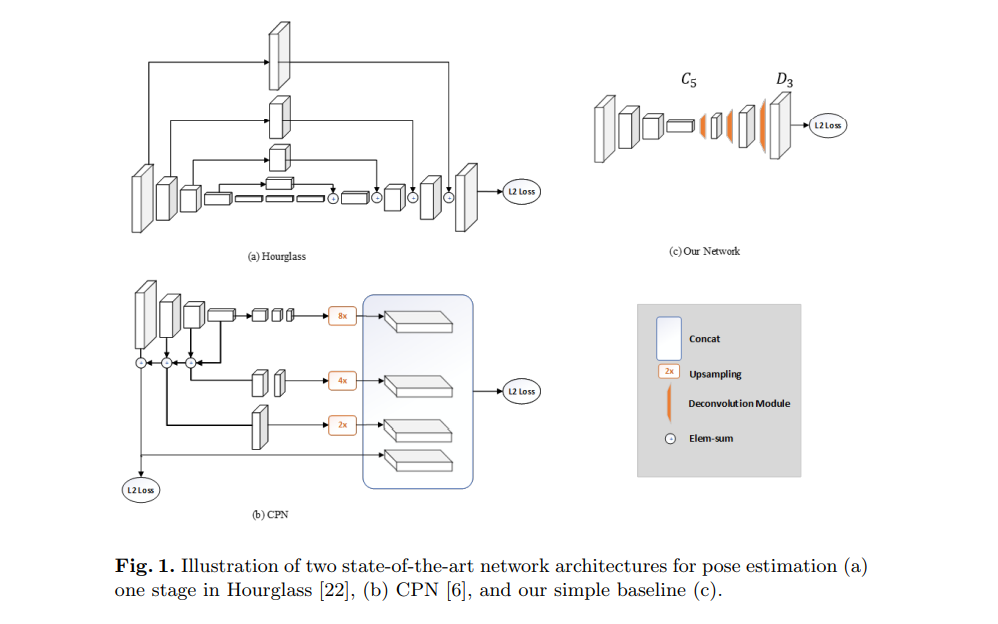
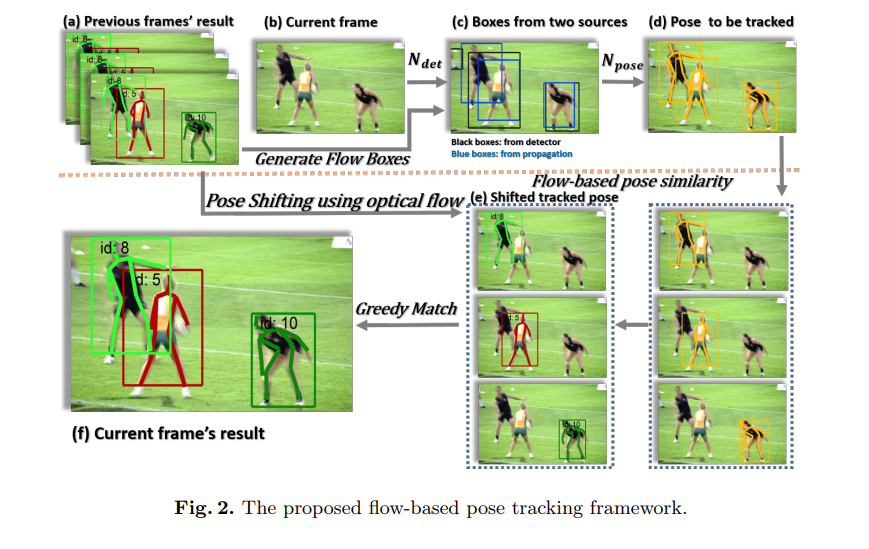
아래의 그림은 제안된 포즈 추적 프레임워크의 흐름을 보여줍니다. 비디오에서 포즈 트래킹은 먼저 사람의 자세를 추정하여 고유한 식별자를 제공한 다음, 프레임을 추적함으로써 이루어집니다.
아래는 이 모델을 다른 모델과 비교한 것이다.

RMPE: Regional Multi-Person Pose Estimation (2018)
이 논문은 사람의 부정확한 경계 상자에서 추정을 위한 지역적 다수-사람의 포즈 추정(Regional multi-person pose estimation) (RMPE) 프레임워크를 제안합니다. 이 프레임워크는 3가지 구성요소로 구성되어 있습니다 : a Symmetric Spatial Transformer Network (SSTN), Parametric Pose NonMaximum-Suppression (NMS) , 그리고 a Pose-Guided Proposals Generator (PGPG) 입니다. 이 프레임워크는 MPⅡ (다수-사람) 데이터셋에 대해서 76.7 mAP 를 달성했습니다. 이 논문의 저자는 중국의 Shanghai Jiao Tong 대학과 Tencent YouTu 소속입니다.
RMPE: Regional Multi-person Pose Estimation
Multi-person pose estimation in the wild is challenging. Although state-of-the-art human detectors have demonstrated good performance, small errors in localization and recognition are inevitable. These errors can cause failures for a single-person pose est
arxiv.org
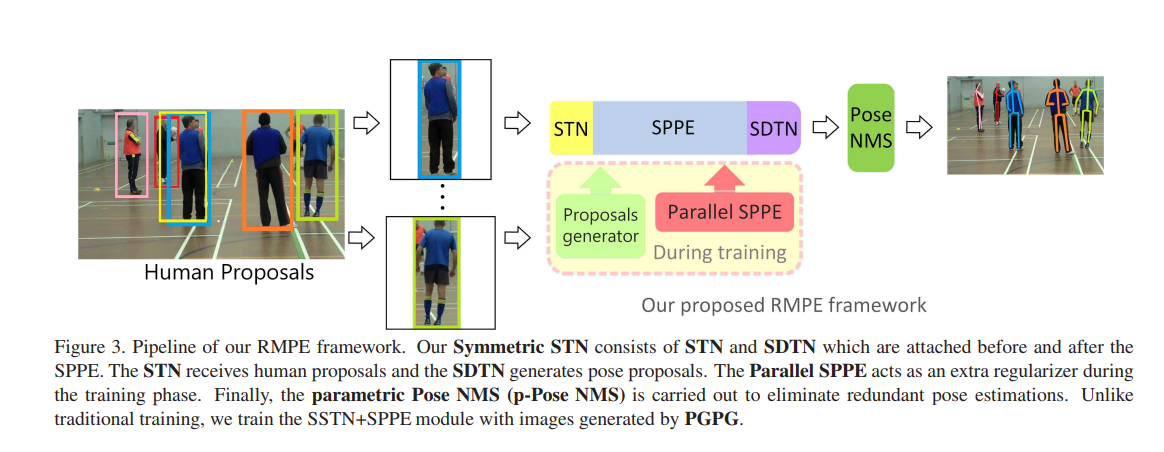
이 프레임워크에서, 사람 탐지기로 부터 얻어진 경계상자는 "Symmetric STN + SPPE" 모둘로 입력됩니다. 그리고나서, 포즈 제안은 자동으로 생성됩니다. 추정된 인간 포즈를 얻기 위해, 이 포즈들은 모수적 포즈 NMS (parametric pose NMS)에 의해 미세 조정됩니다. 학습할 때, 지역 최소치를 피하기 위하여 "병렬 SPPE"가 도입됩니다.

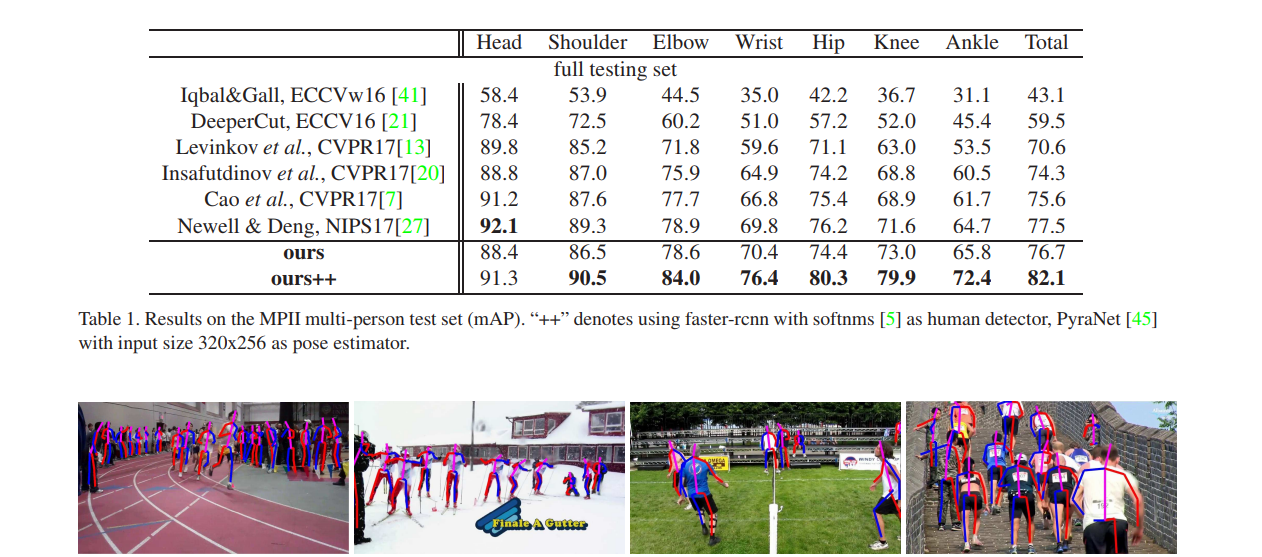
아래의 그림은 다른 프레임워크와 비교하여 모델로 얻어진 포즈 예측치들 뿐만 아니라 모델의 성능도 보여줍니다.
OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields (2019)
OpenPose는 신체, 발, 손, 그리고 얼굴 키포인트를 포함하여 다수 사람의 2D포즈 탐지에 대한 실시간 오픈 소스 시스템입니다. 이 논문에서는 이미지와 비디오에서 2D 사람 포즈를 탐지하는 실시간 접근을 제안합니다. 여기서 제안된 방법은 Part Affinity Fields (PAFs) 라고 알려진 비모수적 표현을 사용합니다. 이 논문의 몇몇 저자는 IEEE소속입니다.
OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
Realtime multi-person 2D pose estimation is a key component in enabling machines to have an understanding of people in images and videos. In this work, we present a realtime approach to detect the 2D pose of multiple people in an image. The proposed method
arxiv.org

아래에 볼 수 있듯, 이 방법은 이미지를 CNN의 입력값으로 사용하고 신체 부분을 탐지하는 신뢰도 맵과 부분 연계(part association)에 대한 PAFs을 예측합니다. 이 논문은 또한 15K의 사람의 발 객체를 가진 주석이 달린 발 데이터셋을 제시합니다. 이 데이터셋은 공개적으로 배포되었습니다.

이 네트워크 아키텍쳐는 부분 대 부분의 연결(파란색으로 표시됨)과 탐지 신뢰도 맵(베이지색으로 표시됨)을 인코딩하는 선호도 필드를 반복적으로 예측합니다.
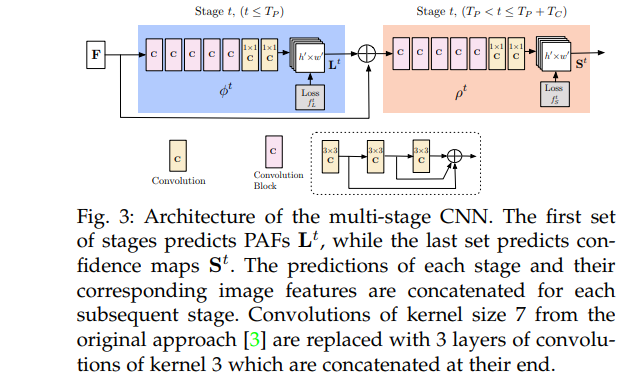
오픈포즈는 또한 다양한 소스에서 이미지를 가져올 수 있는 주변 소프트웨어 및 API입니다. 예를 들어, 카메라 피드, 웹 캠, 비디오, 또는 이미지로 입력값을 선택할 수 있습니다. 이는 Ubuntu, Windows, Mac OS X 그리고 임베딩된 시스템 (e.g., Nvidia Tegra TX2)와 같은 다른 플랫폼에서 작동됩니다. 또한 CUDA GPUs, OpenCL GPUs, 그리고 CPU-only 디바이스와 같은 다른 하드웨어에 대해서도 지원을 제공합니다.
오픈포즈는 신체+발 탐지, 손 탐지, 얼굴 탐지 ; 라는 세가지 블록을 가지고 있습니다. 오픈포즈는 MPⅡ 인간 다수-사람 데이터셋, COCO 키포인트 챌린지 데이터셋, 그리고 논문에서 제안하는 발 데이터셋에 대해서 평가되었습니다. 아래의 그림은 다른 모델과 비교하여 오픈포즈로 얻어진 결과들을 보여줍니다.

Human Pose Estimation for Real-World Crowded Scenarios (AVSS, 2019)
이 논문은 군중에 대한 포즈 추정을 측정하는 방법을 제안합니다. 이러한 인구 밀집 지역에서 자세를 추정하는 어려움에는 서로 근접한 사람들과, 서로 겹쳐서 보이지 않는것 , 그리고 부분적으로 보이는 것들이 포함됩니다. 이 논문의 저자들은 Optronics의 Fraunhofer Institute와 Karlsruhe Institute of Technology KIT 소속입니다.
Human Pose Estimation for Real-World Crowded Scenarios
Human pose estimation has recently made significant progress with the adoption of deep convolutional neural networks. Its many applications have attracted tremendous interest in recent years. However, many practical applications require pose estimation for
arxiv.org

군중 이미지의 포즈 추정을 최적화하기위해 사용된 방법들 중 하나는 backbone으로 ResNet50 네트워크를 사용한 한 사람의 포즈 추정기입니다. 이 방법은 2가지 단계의 top-down접근방식 입니다. 즉, 각 사람들을 지역화하고,그리고 나서 모든 예측치에 대해 한 사람의 포즈 추정을 수행합니다.
이 논문은 또한 두가지 폐색 탐지 네트워크 (occlusion detection networks)를 소개합니다; Occlusion Net과 Occlusion Net Cross Branch 입니다. Occlusion Net은 이전 층에서 관절 표현을 학습할 수 있도록 두개의 전치된(tranposed) 컨볼루젼 후에 분할됩니다. Occlusion Net Cross Branch는 하나의 전치된 컨볼루젼 이후에 분리됩니다. 폐색 탐지 네트워크는 포즈당 두 세트의 히트맵을 출력합니다. 한 히트맵은 눈에 보이는 키포인트들에 대한 것이고, 다른 히트맵은 보이지 않는 키포인트들에 대한 것입니다.
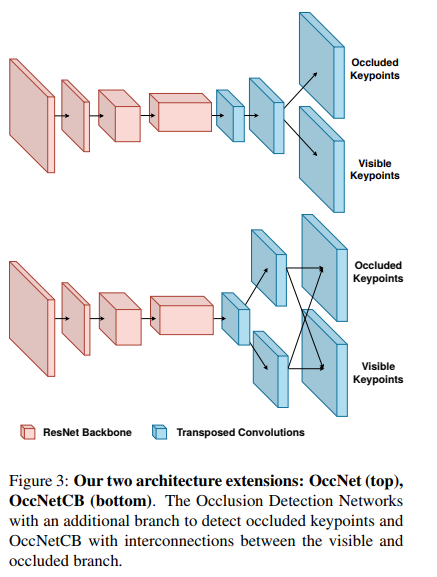
이 테이블은 다른 모델과 비교한 이 모델의 성능을 보여줍니다.

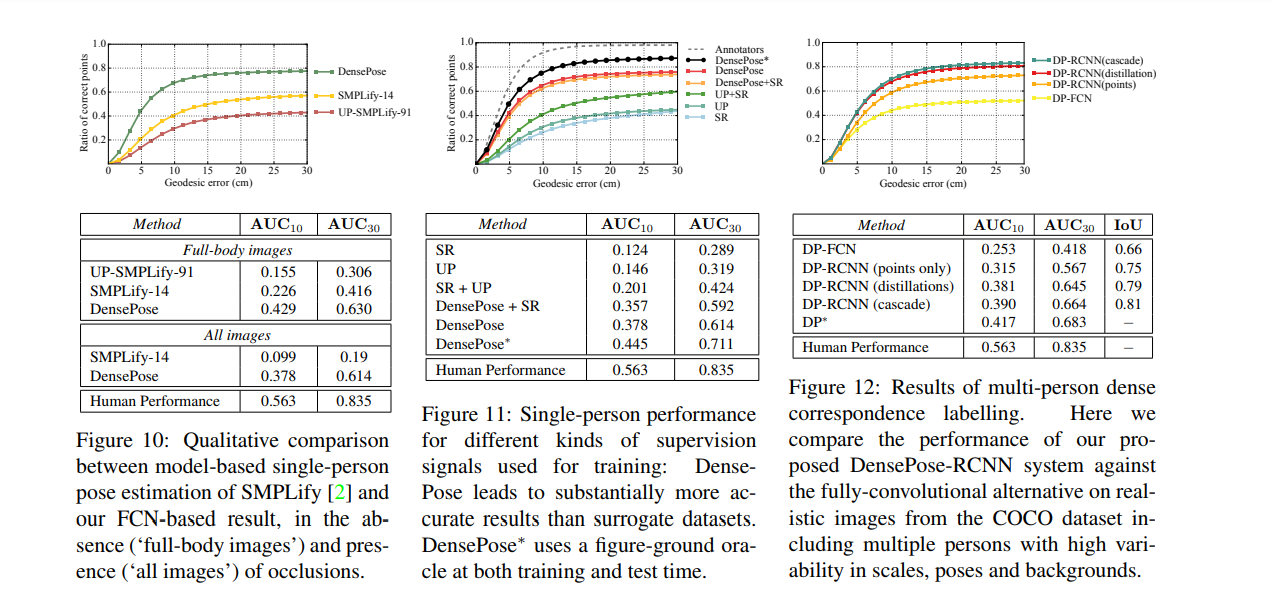
DensePose: Dense Human Pose Estimation In The Wild (2018)
이 논문은 INRIA-CentraleSupelec과 Facebook AI Research로부터 발표되었으며, 그들의 목적은 RGB이미지의 모든 사람의 픽셀들을 사람 신체의 3D 표면에 매핑하는 것이었습니다. 또한 DensePose-COCO dataset을 소개했습니다. 이는 50K COCO 이미지를 이미지 대 표면으로(image-to-surface) 대응시켜 수동으로 주석을 단 데이터셋입니다. 이 저자는 이 데이터셋을 사용하여 배경, 막힘, 규모 변화가 있을 때, 밀도의 대응을 제공하는 CNN 기반 시스템을 학습하였습니다. 대응관계는 기본적으로 한 이미지가 다른 이미지의 픽셀에 대응하는 방식을 나타냅니다.

DensePose: Dense Human Pose Estimation In The Wild
In this work, we establish dense correspondences between RGB image and a surface-based representation of the human body, a task we refer to as dense human pose estimation. We first gather dense correspondences for 50K persons appearing in the COCO dataset
arxiv.org
이 모델에서, 하나의 RGB이미지는 입력값으로 사용되고 표면 점과 이미지 픽셀 사이의 상관관계를 수립하기위해 사용됩니다.
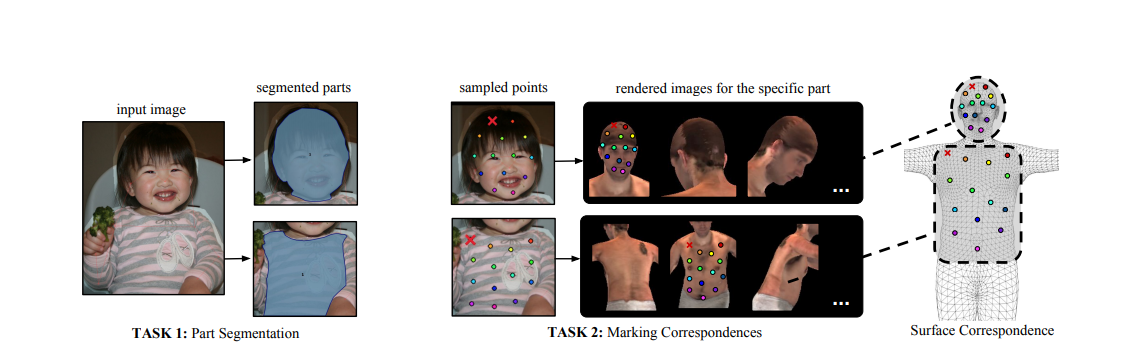
이 모델의 접근방식은 Mask-RCNN 시스템을 결합하여 구성되었습니다. 이 모델은 GTX 1080 GPU 에서는 240 x 320 이미지에 대해 초당 20-26 프레임으로 작동하고, 240 x 320 이미지에 대해 초당 4-5 프레임으로 작동합니다.

저자는 DensePose-RCNN시스템을 다루기 위해 Dense 회귀 (DenseReg) 시스템을 Mask-RCNN 아키텍쳐와 결합하였습니다.
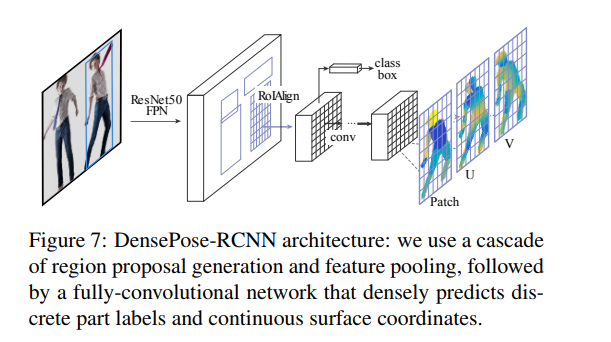
이 모델은 할당(assignment) 및 좌표(coordinate) 예측을 위한 분류 및 회귀 head를 생성하는데 전념하는 완전-컨볼루션 네트워크를 사용합니다. 저자는 MaskRCNN의 키포인트 branch에서 사용된 것과 같은 아키텍쳐를 사용했습니다. 이 모델은 512개의 채널을 가진 8개의 교대(alternating) 3x3 완전 컨볼루션과 ReLU 레이어로 구성되어 있습니다.

저자는 2.3k의 사람을 포함하는 1.5k 이미지 테스트 셋과 48K 사람의 트레이닝 셋으로 실험을 수행했습니다. 아래의 그림은 다른 방법과 비교하여 이 모델의 성능을 비교한 것 입니다.

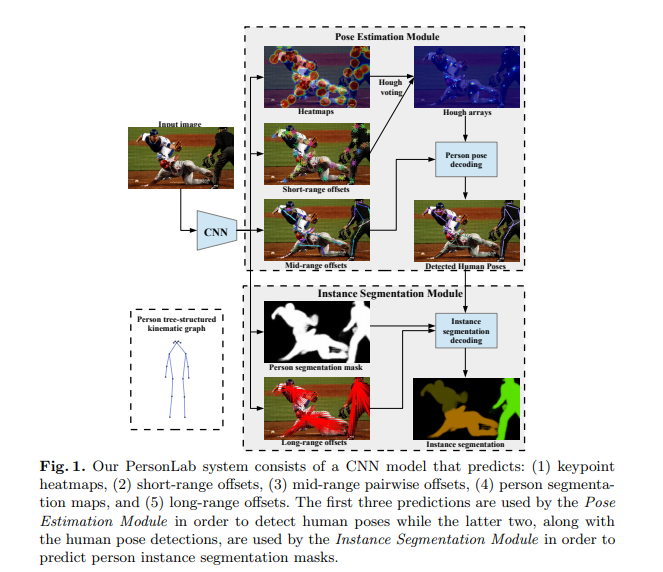
PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model (2018)
이 논문의 저자는 Google 소속입니다. 그들은 포즈 추정을 위한 박스가 없는 bottom-up 접근법과 여러 사람이 있는 이미지에 대한 인스턴스 분할 방법을 제시합니다.

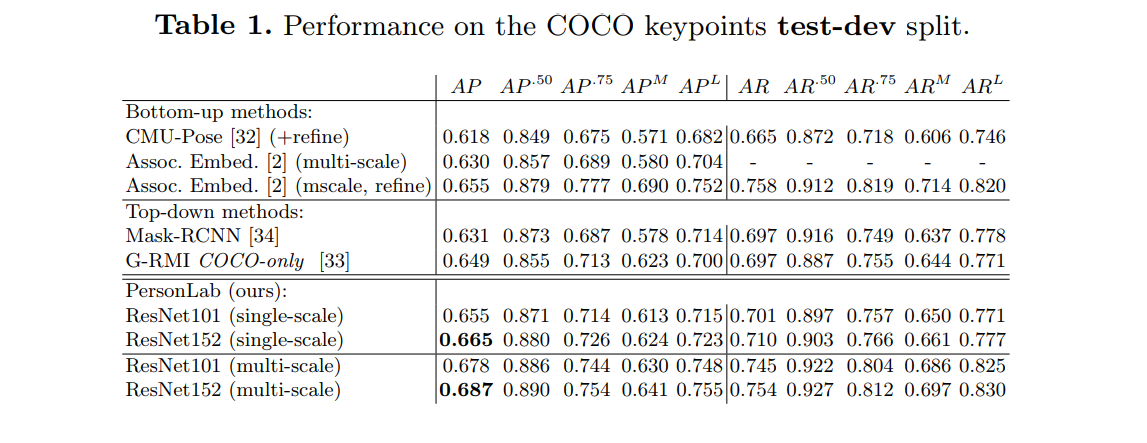
이것은 저자들이 먼저 신체 부분을 탐지한 다음 이 부분들을 사람 객체의 경우로 분류한다는 것을 의미합니다. 이 접근방식은 COCO test-dev 키포인트의 평균 정확도를 단일-규모의 추론으로 0.665를 그리고 다수-규모의 추론으로 0.687로 달성하였습니다.
PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
We present a box-free bottom-up approach for the tasks of pose estimation and instance segmentation of people in multi-person images using an efficient single-shot model. The proposed PersonLab model tackles both semantic-level reasoning and object-part as
arxiv.org
이 논문에서 제안된 모델은 경계가 없는, 완전 합성곱 시스템이며, 먼저 이미지의 모든 개인들에 대한 키포인트를 예측합니다. 이 모델은 COCO keypoint dataset로 학습되었습니다.
키포인트 탐지 단계에서, 이 모델은 이미지 속 사람에 대해 보이는 키포인트를 탐지합니다. PersonLab 시스템은 표준 COCO 키포인트 작업과 오직 사람 클래스에 대한 COCO 객체 분할에 대해서 평가되었습니다.
아래의 그림은 COCO 키포인트 tes-dev 분할 에 대한 모델의 성능을 보여줍니다.
결론
이제 우리는 다양한 맥락에서 인간 자세 추정을 수행하기 위한 가장 일반적인 몇가지 기술, 그리고 아주 최근의 몇가지 기술에 대한 속도를 높여야 합니다.
위에서 언급되고 링크된 논문/요약에는 코드 구현에 대한 링크도 포함되어 있습니다. 이들을 테스트한 후 당신이 얻게될 결과를 기꺼이 확인할 수 있습니다.
'레퍼런스 > Tech : 기술' 카테고리의 다른 글
| i.am.aiAI Expert Roadmap (0) | 2022.11.19 |
|---|---|
| [감정 분석] SENTIWORDNET 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining (번역) (0) | 2021.05.07 |
| [Pose-Estimation] DeepPose: Human Pose Estimation via Deep Neural Networks (번역) (0) | 2021.04.15 |
| [LSTM] LSTM 네트워크 이해하기 (번역) (0) | 2020.11.12 |
| [추천시스템] RFM기법과 연관성 규칙을 이용한 개인화된 전자상거래 추천시스템 논문 요약 (0) | 2020.05.19 |