2021. 4. 15. 11:06ㆍ레퍼런스/Tech : 기술
이 논문은 처음으로, 딥러닝을 통해 포즈 예측이라는 개념을 제시한 논문이라고 한다.
DeepPose: Human Pose Estimation via Deep Neural Networks

그림1. 관절이 극도로 변하는 것 이외에도, 관절의 많은 부분들이 거의 보이지 않습니다. 포즈의 나머지 부분을 보고 사람의 모션이나 움직임을 생각할 수 있기 때문에 우리는 왼쪽 이미지의 오른쪽 팔의 위치를 추론할 수 있습니다. 비슷하게, 오른쪽 그림의 사람의 왼쪽 부분은 거의 보이지 않습니다. 이것은 holistic reasoning (전체론적 추론) 이 필요한 예시중 하나입니다. 우리는 DNN이 자연 스럽게 이런 유형의 추론이 가능하다고 믿습니다.
요약
우리는 깊은 신경망(DNNs) 을 기반으로한 사람 포즈 예측에 대한 방법을 제시합니다. 이 포즈 예측은 신체 관절에 대한 DNN 기반 회귀 문제로 공식화됩니다. 우리는 높은 정확도의 포즈 예측치를 산출하는 일종의 DNN 회귀 분석기를 제시합니다. 이 접근은 전체론적인 방식으로 포즈에 대해 추론하는 장점을 가지고 있으며, 최근 딥러닝의 발전으로 가능하게된 단순하지만 강력한 공식입니다. 우리는 다양한 실제 이미지의 4가지 학술적인 벤치마크에 대해 최신이거나, 더 좋은 성능을 가지는 상세한 경험적 분석을 제시합니다.
1. 도입
사람의 포즈 예측의 문제는, 사람 관절의 위치에 대한 문제로 정의가 되며 , 컴퓨터 비젼 분야에 상당한 관심을 받고 있습니다. 그림1. 에서 누군가는 - 강한 관절들, 작고 거의 보이지 않는 관절들, 보이지 않는 것(occlusions) , 문맥을 파악해야 하는 것 등- 이러한 문제에 대한 도전과제를 봤을지도 모릅니다.
이 분야의 주요 연구 흐름은 주로 첫번째 도전과제, 즉 모든 가능한 관절화된 포즈들을 넓은 공간에서 찾아야 하는 문제, 로 인해 동기부여가 되었습니다. 부분적 기반의 모델은 스스로 자연스럽게 관절들을 모델링 하고, 최근 효율적으로 추론하는 다양한 모델들이 제시되고 있습니다.
그러나, 위의 효율은 제한된 표현력이라는 비용을 지불하고 달성이 됩니다. 즉, 신체 부분들 사이의 모든 상호작용들의 작은 부분 집합들을 모델링 해야 하기 때문에, 신체 부분 당, 지역적 탐지기 (local detector) 를 사용하게 됩니다. (의역) 그림 1. 에서 예를 들었듯이, 이러한 제한사항들이 인지가 되고 있으며, 전체론적인 방식으로 포즈를 추론하는 방식들이 제시가 되고 있습니다. 하지만 실제 문제에서는 성공이 제한적입니다.
이번 연구에서는, 사람 포즈 예측을 전체적인 관점으로 돌릴 것입니다. 최근 딥러닝의 발전으로 가능하게 되었으며, 깊은 신경망 (DNN)을 기반으로 하는 신기한 알고리즘을 제안합니다. DNN은 시각적 분류 작업과 최근 객체 지역화 (object localization) 에 훌륭한 성능을 보입니다. 그러나, 관절이 있는 물체에 대한 정확한 지역화에 대해 DNN을 적용하는 질문에 대해서는 여전히 답해지지 않은 채로 남아있습니다. 이번 연구에서, 우리는 이 질문에 빛이 보이길 시도 했으며, DNN을 사용한 전체론적인 사람 포즈 예측 이라는 단순하지만 강력한 공식을 제안합니다.
우리는 포즈 예측을 관절 회귀 분제라고 공식화 했으며 어떻게 성공적으로 그것을 DNN 세팅에 녹일 것인지 보여주겠습니다. 각 신체 관절의 위치는 전체 이미지와 7 층의 포괄적인 합성곱 DNN의 입력 값으로 회귀될 것입니다. 이 공식에 두가지 장점이 있습니다. 첫번째로 DNN은 각 신체 관절의 전체 문맥을 포착하는 것이 가능합니다 - 즉, 각 관절의 regressor 는 전체 이미지를 신호로 사용합니다. 두번째로, 이 접근은 그래픽적인 모델들 보다 상당히 더 단순한 접근입니다. 즉, 정확한 디자인 피쳐 재현과 부분적인 탐지도 필요 없습니다; 또한 모델 토폴로지와 관절 간의 상호작용을 정확하게 디자인할 필요도 없습니다. 대신에, 유전학적인 컨볼루젼 DNN이 이 문제에 대해 학습될 수 있다는 것을 보여드리겠습니다.
더 나아가, 우리는 DNN 기반의 포즈 예측기 (pose-predictors)의 일종을 제안합니다. 이런 일방적인 배열 덕분에 관절의 위치에 대한 정확도가 높아질 수 있습니다. 전체 이미지에 기반한 초기 포즈 예측에 대해 시작하기 위해, 우리는 더 높은 해상도의 하위 이미지를 사용하여 관절 예측을 구체화하는 DNN 기반 회귀분석을 학습하게 되었습니다.
우리는 모든 보고된 결과들에 대한 4가지 벤치마크 보다 더 낫거나 혹은 최신의 결과를 보여드리겠습니다. 우리의 접근 방식은 관절 뿐만 아니라, 외모에서 강한 변화를 보이는 사람들의 이미지에서도 잘 수행된다는 것을 보여줍니다. 마지막으로, 크로스-데이터셋 평가를 통해 성능을 일반화한 것을 보여드리겠습니다.
2. 관련 연구
일반적으로 관절형 물체를 표현하고 특히 인간의 자세를 나타내는 아이디어는 컴퓨터 비전의 초기부터 주장되어왔습니다. Fishler 와 Elschlager에 의해 도입된 소위 Pictorial Strictures라고 불리는 것은 Felzenszwalb 와 Huttenlocher에 의해 거리 변환 기술을 사용하여, 다루기 쉽고 실용적으로 만들어졌습니다. 결과적으로, 실용적으로 중요한 PS-기반의 모델의 변이가 상당히 개발되었습니다.
위에서 다룬 다루기 쉬운 성질은, 이미지 데이터에 의존한 것이 아닌, 바이너리 성질을 가진 트리 기반의 포즈 모델이라는 제한적인 제약이 따릅니다. 결과적으로 연구는 다루기 쉬운 성질을 유지하면서 모델의 대표성을 강화하는데 초점을 맞추게 되었습니다. 이를 달성하고자 하는 초기의 시도들은 풍부한 부분 탐지기에 근거하였습니다. 더욱 최근에는 복잡한 관절의 관계들을 표현하는 다양한 분야의 모델들이 제안되었습니다. Yang and Ramanan은 부분에 대한 혼합 모델을 사용했습니다. PS 모델을 혼합하여 전체 모델 척도의 혼합 모델은 Johnson과 Everingham에 의해 연구되어 왔습니다. 보다 풍부한 고차 공간 관계는 Tian 등에 의해 계층적 모델에서 포착되었습니다. 고차 관계(higer order relationship)를 포착하기 위한 다른 접근 방식은 글로벌 분류기에 의해 추정된 이미지 의존적인 PS모델이 있습니다.
전체적인 방식으로 포즈에 대한 추론한다는 우리의 생각은 제한된 실용성을 보여주었습니다. Mori 와 Malik는 각 테스트 이미지에 대해 레이블이 지정된 이미지 집합에서 가장 가까운 예를 찾고 접합 위치를 보내려고 했습니다. 유사한 근접 이웃 세팅하는 것은 Shakhnarovich에 의해 개발되었습니다. 하지만 이들은 지역에 민감한 해싱을 사용합니다. 더욱 최근에는 Gkioxari et al. 이 부분 배열에 관련한 반 - 글로벌 분류기를 제안했습니다. 이 공식은 현실의 이미지에서 매우 좋은 결과를 보이나, 선형 분류기에 근거한 것으로 우리의 것보다 표현이 덜 되었습니다. 그리고 팔에 대해서만 테스트 되었습니다. 마지막으로 포즈 회귀에 대한 아이디어는 Ionescu et al. 에 의해 개발되었지만, 그들은 3D 포즈에 대해 추론 했습니다.
우리와 가장 가까운 연구는 컨볼루젼 NN을 이웃 구성요소 분석 (Neighbrohood Component Analysis) 와 함께 사용하여 포즈를 나타내는 임베딩 지점으로 회귀합니다. 그러나, 이 연구는 일방적인 네트워크를 적용하지 않았습니다.
DNN 회귀의 흐름은 위치를 탐지하기 위해 사용이 되어왔으나, 얼굴 지점에만 해당합니다. 얼굴 포즈 추정에 대한 관련된 문제는 Osadchy et al. 이 대조적인 손실과 함께 학습된 NN 기반의 포즈 임베딩을 적용했습니다.
3. 포즈 예측을 위한 딥러닝 모델
우리는 다음의 기호를 사용하도록 하겠습니다. 포즈를 표현하기 위해서 k개의 신체 관절에 대한 위치를 pose vector라고 정의하여 인코딩 하겠습니다.

y : 포즈 벡터, 는 i번째 관절의 (x,y) 좌표
라벨된 이미지는

라고 정의하며, x는 이미지 데이터를 나타내고 , y는 포즈벡터의 ground truth 입니다.
또한, 관절의 좌표가 정확히 이미지 좌표의 안에 있기 때문에, 신체 몸이나 일부를 둘러싸는 박스 b에 대해 관절의 좌표를 정규화하는 것이 도움이 됩니다. 사소한 경우에, 박스가 이미지 전체를 표시할 수도 있습니다. 그런 박스는

c : center , w : width, h : height , b로 정의될 수 있습니다.
그리고 나서 관절

는 박스의 중심으로 번역이 되고, b로 정규화된 것으로 우리가 언급한 박스 사이즈에 의해 스케일 됩니다.

더 나아가서, 우리는 포즈 벡터의 요소에 같은 정규화를 적용할 수 있습니다.

정규회된 포즈벡터로 결과값을 내도록요.
마지막으로, 약간의 표기법을 남용해서, 우리는 바운딩 박스 b에 의해 잘려진 이미지 x 표시하기 위해서

를 사용하겠습니다. 이는 상자에 의해 이미지를 사실적으로 정규화 합니다.
간결성을 위해 우리는 b를 전체 이미지 상자인 N(.) 정규화로 나타내겠습니다.
3.1 DNN 기반의 회귀를 사용한 포즈 예측
이번 연구에서는 우리는 포즈 예측의 문제를 회귀로 다룹니다. 여기서 우리는 함수

를 사용하며, 여기에서 각 이미지 x 에 대해 종규화된 포즈 벡터를 회귀합니다. 여기의 θ 기호는 모델의 파라미터로 표시합니다. 그래서 식(1) 로 부터 정규화 변형을 사용합니다. 이미지 좌표값 안에 있는 포즈 예측치 y*는 다음과 같습니다.

비록 이것이 단순한 변형임에도 불구하고, 이 방법의 힘과 복잡도는 ψ에 있습니다. 이는 컨볼루젼 깊은 신경 망(DNN)에 기반한 것입니다. 이런 신경망 네트워크는 몇가지 레이어들로 구성되어있습니다. 즉 - 각 변환은 비선형 변환 다음에 이어지는 선형 변환입니다. 첫번째 레이어는 미리 정의한 사이즈의 이미지를 입력값으로 취하고, pixels 수 * 3 개 채널 과 같은 크기를 가집니다. 마지막 레이어는 회귀의 타겟 값을 출력합니다. 우리의 경우 2k의 관절 좌표 입니다.
우리는 이미지 분류에 대한 Krizhevsky 등에 의한 연구에 있는 ψ 구조에 근거했습니다. 왜냐하면, 이 논문은 물체 위치화에 놀라운 결과를 보여줬기 때문입니다.

그림2. 왼쪽: DNN 기반 포즈 회귀 분석의 개략적 뷰 . 우리는 네트워크 층을 그들에 상응하는 차원과 함께 시각화 하였습니다. 여기에서 합성곱 층은 파란색이고, fully connected 는 초록색입니다. free layer의 파라미터는 보여주지 않았습니다. 오른쪽 : 각 단계 s에서, 이전 단계로 부터 예측치를 수정하기 위해, 각 이미지에 대해서, 회귀를 정제하는 것이 적용됩니다.
용건만 간단히 하자면, 네트워크는 7개의 레이어로 구성되어 있습니다. (왼쪽 그림 2)
C로 표기한 것은 콘볼루젼 레이어입니다. LRN으로 표기한 것은 지역 반응 정규화 레이어 (local response normalization layer) 이고, P는 풀링 레이어로 표기했고, F 는 완전 연결 층(fully connected layer) 으로 표기했습니다.
오직 C랑 F레이어는 학습 가능한 파라미터를 포함하고 있지만, 나머지 파라미터는 자유롭습니다. C와 F 레이어 둘다 선형 변형 (linear transformation) 을 포함하고 있습니다. 그 후에 비선형 것이 뒷 따라 오구요. 이는 우리의 경우 rectified linear unit이라고 합니다. ( 선형 유닛을 바로 잡는 ?) C 층에 대해서는 크기는 width x height x depth로 고정됩니다. 여기에서 첫번째 두 치수는 공간적 의미를 갖는 반면 깊이는 필터 수를 정의합니다. 만약에 우리가 각 레이어의 사이즈를 괄호 안에 넣어서 적게 된다면 , 네트워크는 정확하게 다음과 같이 설명될 수 있습니다.
C(55*55*96) - LRN - P - C(27*27*256) - LRN - P - C(13 * 13 * 384) - C(13 * 13* 384) - C(13*13*256) - P - F(4096) - F(4096)
첫번째 두 C 층의 필터 크기는 11 * 11 이고 5 * 5 입니다. 그리고 남은 세가지는 3 * 3 입니다.
풀링은 세가지 레이어 후에 적용되며, 해상도의 감소에도 불구하고 성능 향상에 기여합니다. 넷의 입력은 (220 x 220) 이고 stride 는 4 이며, 이것이 신경망에 입력됩니다.
위 모델의 전체 파라미터의 수는 대략 40M 정도 됩니다. 상세한 설명을 위해서 독자들에게 [14]를 읽어보길 추천합니다.
포괄적인 DNN 구조의 사용은 분류와 위치화 문제에 대한 두개의 놀라운 결과에 의해 동기부여가 되었습니다. 실험 섹션에서 우리는 이런 포괄적인 구조가 모델을 학습하기 위해서 사용될 수 있으며, 결과적으로 포즈 예측에 대해 최신의 혹은 더 좋은 성능을 낸다는 것을 보여줄 것입니다. 더 나아가 이러한 모델은 진짜 전체적인 것입니다. 즉 마지막 관절 위치 추정이 복합적으로 전체 이미지의 비선형 변환에 근거한다는 것입니다.
추가적으로, DNN을 사용하면 도메인 별 포즈 모델을 설계할 필요가 없습니다. 대신에, 이런 모델과 피쳐는 데이터로 부터 학습됩니다. 비록 회귀 손실이 관절 사이의 명시적 상호작용을 정확하게 모델링 하지는 않지만, 이런 상호작용은 7개의 숨겨진 계층에 의해 암시적으로 포착됩니다. - 즉, 모든 내부 feature는 모든 관절 회귀에 의해 공유가 됩니다.
Training
[14]와의 차이점은 손실입니다. 분류 손실을 사용하는 대신에, 우리는 마지막 네트워크의 맨 위에 포즈 벡터를 예측하는선형 회귀를 예측치와 true 포즈 벡터 사이의 L2 거리를 최소화 하면서 학습 시켰습니다. ground truth 포즈 벡터가 이미지 좌표와 포즈의 절대값으로 정의되었기 때문에, 이미지 마다 사이즈가 다양합니다. 그래서 우리는 등식 (1) 정규화를 사용하여 우리의 트레이닝 셋 D를 정규화 합니다.
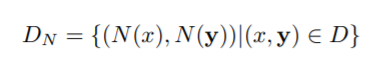
그런 다음 최적의 네트워크 매개 변수를 얻기 위한 L2 손실은 다음과 같습니다.
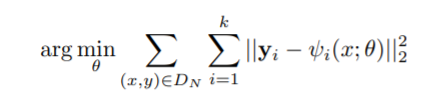
오차 제곱의 합 밑에 이거랑 같은거임

명확한 구별을 위해 개별 관절에 대한 최적화를 기록합니다. 일부 이미지의 경우, 일부 조인트에 레이블이 붙어 있지 않더라도, 위의 목표는 사용할 수 있다는 점에 유의해야합니다. 이번 경우에, 합계의 해당 항은 생략됩니다. 위 파라미터 θ는 온라인 구현에서 설명되었던 Back-propagation을 사용하여 최적화됩니다. 각 mini-batch 크기는 128이고, 적응형 기울기 업데이트가 (adaptive gradient updates) 계산됩니다. 가장 중요한 파라미터인 learning rate는 0.0005로 셋팅 되었습니다. 모델이 매개변수의 수가 크고, 사용된 데이터셋이 상대적으로 작은 크기이기 때문에 우리는 무작위로 번역된 많은 이미지 데이터를 사용하여 데이터를 증대(augment) 합니다. (sec. 3.2를 보세요). left/right flips, F 층 에 대한 Dropout 정규화 는 0.6으로 세팅합니다.
3.2 일방적인 포즈 회귀
이전 섹션으로부터 포즈 공식은 관절 추정이 이미지 전체에 기반했고, 문멕에 의존한다는 이점을 가지고 있습니다. 그러나 220 * 220의 고정된 이미지 크기 때문에, 네트워크는 세부사항을 볼 수 있는 제한된 용량을 가지고 있습니다. 즉, 거친 스케일에서 포즈 속성을 포착하는 필터를 학습합니다. 이는 거친 포즈를 추정하기 위해 필요하지만 항상 신체의 관절을 정확히 위치화 하기에는 불충분합니다.
입력 크기를 쉽게 늘릴 수는 없습니다. 왜냐하면 이렇게 하면 많은 수의 매개변수들이 증가하기 때문입니다. 더낳은 정확도를 달성하기 위해 우리는 일련의 포즈 회귀를 학습하는 것을 제안합니다.
첫번째 단계에서 시작은 이전 섹션에서 설명한 초기 포즈를 추정함으로써 시작합니다. 그 다음 단계에서 추가 DNN 회귀 분석기가 관절의 위치가 이전 단계에서 실제 위치로 위치가 변화하는 것을 예측 하기위해대해 학습됩니다. 그래서 각각의 후속 단계는 그림2와 같이 현재 예측된 포즈의 정교함으로 생각할 수 있습니다.
더 나아가 각각의 후속 단계는 상대적인 이미지의 부분에 대해 집중하기 위해서 예측된 관절의 위치를 사용합니다. 하위 이미지는 이전 단계에서 예측돤 관절의 위치 주위에 자르고 이 관절에 대한 포즈 변위 회귀가 이 하위 이미지에 적용됩니다. 이러한 방식으로 후속의 포즈 회귀가 고해상도 이미지를 보게됩니다. 그래서 정교한 스케일의 feature를 학습하게 되고 궁극적으로 높은 성능을 가져오게 됩니다.
우리는 모든 일련의 스테이지에 서 같은 네트워크 구조를 사용했습니다. 하지만 다른 네트워크 파라미터를 학습했습니다. 전체 S의 각 단계 s ∈ {1, ... , S} 에서 , 학습된 네트워크 매개변수를 θs 로 표시했습니다. 그래서, 포즈의 변위 회귀는

를 읽습니다. 주어진 관절의 위치 yi를 다듬기 위해 우리는 yi 주변의 하위 이미지를 포착하는 관절 바운딩 박스 bi를 고려할 것입니다.
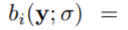

i 번째 관절의 중심점을 가지고 있고, 포즈 다이어미터의 차원을 σ 로 스케일 했습니다.
포즈의 다이어미터 diam(y)는 왼쪽 어깨와 오른쪽 엉덩이와 같은 사람 몸통에 있는 반대쪽 관절 사이의 거리로 정의되며, 구체적인 포즈 정의와 데이터 세트에 따라 달라집니다.
위의 기호를 사용해서 단계 s = 1 에서 전체 이미지를 포함하거나 사용자 디텍터에 의해 얻어진 바운딩 박스 b0으로 시작합니다. 우리는 초기 포즈를 얻게 됩니다.

이전 단계 (s-1)로 부터

로 정의된 하위 이미지에 대해 회귀를 적용함으로써
모든 관절 i ∈ {1, ... , k} 에 대해 각 후속 스테이지 s ≥ 2 에서는, 변위를 조정하는 것을 향해 첫번째로 회귀합니다.


그리고 나서 관절의 새로운 박스를 추정합니다.


우리는 이 일련의 과정을 고정된 단계 수 S 로 적용합니다. 이는 Sec. 4.1에서 설명됩니다.
Training
네트워크 파라미터 θ1 은 Sec. 3.1 Eq (4) 에서 설명된 대로 학습됩니다. 하위 스테이지 s ≥ 2 에서 , 학습과정은 하나의 중요한 차이와 동일하게 수행됩니다. 학습 예제

로 부터 각 관절 i는 다른 바운딩 박스를 사용해서 정규화 됩니다.

이전 단계에서 얻은 동일한 접합부의 예측에 중심을 둔것으로, 이전 단계의 모델에 기초하여 스테이지의 훈련을 조건화 합니다.
딥 러닝 방식이 큰 용량을 가지기 때문에, 우리는 각 이미지와 관절에 대해 다수의 정규화 기법들을 사용하여 학습데이터를 증진시킵니다. 이전의 스테이지로부터 예측치를 사용하는 것 대신에, 시뮬레이션된 예측값을 생성합니다. 이는 훈련데이터의 모든 예시들에 걸쳐 관측된 변위(y(s-1)i - yi)의 평균과 분산과 동일한 평균과 분산을 가진 2차원 정규분포 N(s-1)i에서 무작위로 샘플링된 벡터에 의해 관절의 실제위치를 임의로 이동함으로써 이루어집니다. 전체 증진 훈련 데이터는 먼저 균일한 원본 데이터에서 예시와 관절을 샘플링한다음 N(s-1)i에서 샘플링된 변위 δ 를 기반으로 시뮬레이션된 예측을 생성함으로써 정의될 수 있습니다.
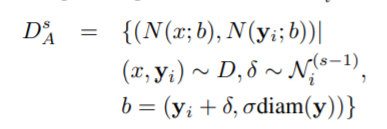
일련의 단계 s 에 대한 트레이닝 목표는 Eq(4)에 의해 수행되며, 각 관절에 대해 올바른 정규화를 사용하도록 각별히 주의해야합니다.

'레퍼런스 > Tech : 기술' 카테고리의 다른 글
| [감정 분석] SENTIWORDNET 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining (번역) (0) | 2021.05.07 |
|---|---|
| 사람 포즈 추정에 대한 2019년도 가이드 (번역) (0) | 2021.04.20 |
| [LSTM] LSTM 네트워크 이해하기 (번역) (0) | 2020.11.12 |
| [추천시스템] RFM기법과 연관성 규칙을 이용한 개인화된 전자상거래 추천시스템 논문 요약 (0) | 2020.05.19 |
| [예측분석] 특허 분쟁리스크 예측모델 개발 연구(2017) 논문 요약 (0) | 2020.05.02 |