[신경망] RNN을 이용한 다음 단어 완성 알고리즘 코드
2020. 5. 1. 10:59ㆍ노트/Python : 프로그래밍
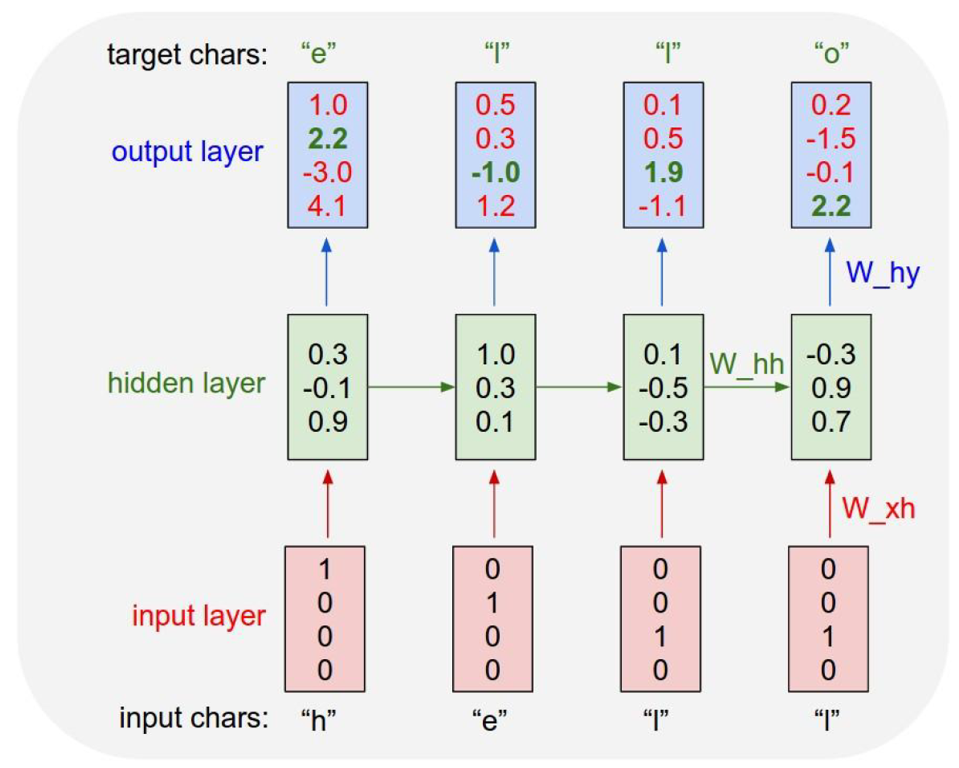
개념 참고 포스팅
코드
# wood -> 학습 -> 모델
# woo 입력 -----> 모델 -> d 예측
# wop 입력 -----> 모델 -> d 예측 (인공지능)
# 알파벳 문자 리스트 대입
char_arr = []
for i in range(97,123):
char_arr.append(chr(i))
char_arr
num_dic = { char_arr[n] : n for n in range(26) }
# 다른방법
num_dic = { n : i for i , n in enumerate(char_arr)}
dic_len = len(num_dic)
학습 데이터 생성
seq_data =['word', 'wood', 'deep', 'dive', 'cold', 'cool', 'load', 'love', 'kiss', 'kind' ]
def make_batch(seq_data):
input_batch = []
target_batch = []
for seq in seq_data:
myinput = [num_dic[n] for n in seq[:-1]]
# print(myinput)
mytarget = num_dic[seq[-1]]
# 원핫인코딩
input_batch.append(np.eye(dic_len)[myinput])
target_batch.append(mytarget)
return input_batch, target_batch
input_batch, target_batch = make_batch(seq_data)
# softmax_cross_entropy_wirh_logits 함수는
# label값을 one-hot 인코딩으로 넘겨줌
# sparse_softmax_cross_entropy_wirh_logits 함수는
#label 값이 one- hot 인코딩이 안된 경우에 사용
모델 변수 정의
# 변수 선언
lr = 0.01
n_hidden = 128 # 셀 출력 갯수
total_epoch = 30 # 에폭
n_step = 3 # 입력 3글자
n_input = n_class = dic_len # 26, 입력크기(n_input) , 클래스 종류 갯수 (n_class)
tf.reset_default_graph()
# 신경망 모델 구성
x = tf.placeholder(tf.float32,[None, n_step, n_input])
# None:: 전체 단어의 수
# n_step : 3글자 입력,
# n_input : 26개 종류
y = tf.placeholder(tf.int32,[None]) # 원핫인코딩이 안되있는 경우
# y = tf.placeholder(tf.float32,[None,n_class]) # 원핫인코딩이 되어있는 경우
w = tf.Variable(tf.random_normal([n_hidden,n_class]))
b = tf.Variable(tf.random_normal([n_class]))
cell1 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden)
cell1 = tf.nn.rnn_cell.DropoutWrapper(cell1, output_keep_prob = 0.5)
cell2 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden)
multi_cell = tf.nn.rnn_cell.MultiRNNCell([cell1,cell2])
# rnn망을 구상
outputs , states = tf.nn.dynamic_rnn(multi_cell, x , dtype=tf.float32)outputs=tf.transpose(outputs, [1,0,2])
# (10,3,128) => (3,10,128)
outputs=outputs[-1]
# (10,128)
sess= tf.Session()
sess.run(tf.global_variables_initializer())
print(sess.run(outputs, feed_dict={x:input_batch}).shape)
모델 트레이닝
model = tf.matmul(outputs, w ) + b
# (10,128) (128,26) => (10,26)
cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits= model, labels=y))
opt = tf.train.AdamOptimizer(lr).minimize(cost)
sess= tf.Session()
sess.run(tf.global_variables_initializer())
for epoch in range(total_epoch):
_,cv = sess.run([opt,cost], feed_dict = {x:input_batch, y:target_batch})
print( "epoch", "%04d" %(epoch+1), "cost","{:.5f}".format(cv))
print("모델 작성 완료 ")
>>>
epoch 0001 cost 0.00014
epoch 0002 cost 0.00017
epoch 0003 cost 0.00015
epoch 0004 cost 0.00024
epoch 0005 cost 0.00104
epoch 0006 cost 0.00010
epoch 0007 cost 0.00023
epoch 0008 cost 0.00007
epoch 0009 cost 0.00022
epoch 0010 cost 0.00042
epoch 0011 cost 0.00071
epoch 0012 cost 0.00032
epoch 0013 cost 0.00004
epoch 0014 cost 0.00003
epoch 0015 cost 0.00054
epoch 0016 cost 0.00015
epoch 0017 cost 0.00002
epoch 0018 cost 0.00009
epoch 0019 cost 0.00002
epoch 0020 cost 0.00020
epoch 0021 cost 0.00002
epoch 0022 cost 0.00024
epoch 0023 cost 0.00005
epoch 0024 cost 0.00010
epoch 0025 cost 0.00016
epoch 0026 cost 0.00223
epoch 0027 cost 0.00003
epoch 0028 cost 0.00008
epoch 0029 cost 0.00020
epoch 0030 cost 0.00007
모델 작성 완료pred= tf.cast(tf.argmax(model,1), tf.int32)
predCheck= tf.equal(pred,y)
accuracy = tf.reduce_mean(tf.cast(predCheck,tf.float32))
input_batch , target_batch = make_batch(seq_data)
pv, av= sess.run([pred, accuracy], feed_dict = {x:input_batch, y:target_batch})
predict_words=[]
for i , v in enumerate(seq_data):
last_char = char_arr[pv[i]]
predict_words.append(v[:3]+last_char)
print("예측결과\n")
print("입력값:", [w[:3] for w in seq_data])
print("예측값:", predict_words)
print("정확도:", av)
예측결과
입력값: ['wor', 'woo', 'dee', 'div', 'col', 'coo', 'loa', 'lov', 'kis', 'kin']
예측값: ['word', 'wood', 'deep', 'dive', 'cold', 'cool', 'load', 'love', 'kiss', 'kind']
정확도: 1.0
단어완성 확인
# dea 입력 -> p??
# luv 입력 -> e??
x = input()
print("입력값:", x)
predict_words=[]
for i , v in enumerate(list(x)):
last_char = char_arr[pv[i]]
print(v)
predict_words.append(v[:3]+last_char)
print("예측값", predict_words)'노트 > Python : 프로그래밍' 카테고리의 다른 글
| [신경망] RNN을 이용한 주식가격 예측 알고리즘 코드 (0) | 2020.05.07 |
|---|---|
| [신경망] RNN을 이용한 단어 번역 알고리즘 코드 (0) | 2020.05.01 |
| [텐서플로우] MNIST 데이터를 이용한 RNN 모델 (0) | 2020.04.30 |
| [케라스] Fashion-Mnist 데이터를 이용한 분류 예측 (성능향상필요) (0) | 2020.04.28 |
| [케라스] Fashion-Mnist 기반 CNN모델 코드 (0) | 2020.04.28 |