[케라스/텐서플로우] 주택가격 예측하기 코드
2020. 4. 23. 13:02ㆍ노트/Python : 프로그래밍


라이브러리 호출
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
케라스버전
데이터 불러오기
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.datasets import boston_housing
(trainData, trainTarget),(testData, testTarget) = boston_housing.load_data()
print(trainData.shape) # (404, 13)
print(trainTarget.shape) # (404,)
print(testData.shape) # (102, 13)
print(testTarget.shape) #(102,)
# 모델 검증 데이터 분류
ValData=trainData[304:,:]
ValTarget=trainTarget[304:]
p_trainData=trainData[:304,:]
p_trainTarget=trainTarget[:304]
모델 생성
# 모델 구성
model = Sequential()
model.add(Dense(units=30, input_dim=13,activation="relu"))
model.add(Dense(units=10,activation="relu"))
model.add(Dense(units=1))
# 모델 학습
model.compile(loss="mse", optimizer= 'rmsprop', metrics=['mae'])
from keras.callbacks import EarlyStopping
es =EarlyStopping(patience=20)
seed= 123
np.random.seed(seed)
tf.set_random_seed(seed)
hist = model.fit(trainData,trainTarget, epochs=10, batch_size=30, callbacks=[es],
validation_data=(ValData,ValTarget))
# 검증결과 출력
print("loss:"+ str(hist.history['loss']))
print("MAE:"+ str(hist.history['mae']))
>>>
loss:[4047.806107020614, 836.5637676881091, 390.45693002832996, 249.5056139502195, 182.78083068545502, 138.7186091583554, 108.03168007878973, 88.64472017193785, 77.60753329437559, 71.6355998020361]
MAE:[56.961746, 25.148031, 16.852732, 13.033249, 10.752718, 8.986338, 7.559703, 6.517845, 6.216516, 5.886183]
모델 테스트
# 모델 테스트
res = model.evaluate(testData, testTarget, batch_size=32)
print("loss")
print(res[0])
print("mae")
print(res[1])
>>>
102/102 [==============================] - 0s 39us/step
loss
73.26150662291283
mae
6.013505935668945모델 사용
#7 모델 사용
xhat = testData
yhat = model.predict(testData)
%matplotlib notebook
plt.figure()
plt.plot(yhat, label = "predicted")
plt.plot(testTarget ,label = "actual")
plt.legend(prop={'size': 20})
print("Evaluate : {}".format(np.average(np.sqrt((yhat - testTarget)**2))))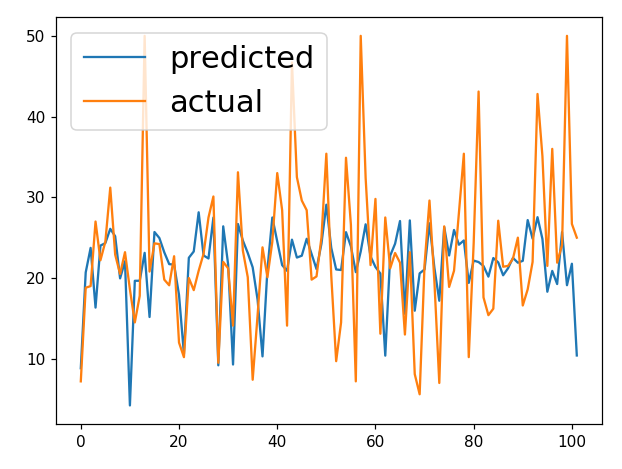
텐서플로우버젼
라이브러리 호출
from keras.datasets import boston_housing
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
from tensorflow.examples.tutorials.mnist import input_data데이터 불러오기
(trainData, trainTarget),(testData, testTarget) = boston_housing.load_data()
변수 및 함수 정의
x =tf.placeholder(tf.float32,shape=[None,13])
y =tf.placeholder(tf.float32,shape=[None])
#xavier(재비어)알고리즘 기반 weight 초기화
w1 = tf.get_variable("w1", shape=[13,30], initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.Variable(tf.random_normal([30]))
l1 = tf.nn.relu(tf.matmul(x,w1)+b1)
w2 = tf.get_variable("w2", shape=[30,10], initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.Variable(tf.random_normal([10]))
l2 = tf.nn.relu(tf.matmul(l1,w2)+b2)
w3 = tf.get_variable("w3", shape=[10,1], initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.Variable(tf.random_normal([1]))
hf = tf.matmul(l2,w3)+b3# 비용함수
cost =tf.sqrt(tf.reduce_mean(tf.square(hf-y)))
# 트레이닝 함수
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
def numIter(data):
return int(len(data)/ batch_size )
# 정확도
accuracy = tf.sqrt(tf.reduce_mean(tf.square(hf - y)))
모델 학습 및 검증
#parameter 설정
trainingEpochs=8
batch_size=1
sess=tf.Session()
sess.run(tf.global_variables_initializer())
for epoch in range(trainingEpochs):
avgCost=0
totalBatch=int(numIter(trainData)/batch_size)
pbar=tqdm(range(totalBatch))
for i in pbar: #in range(totalBatch):
# batchX,batchY=mnist.train.next_batch(batch_size)
cv,_,hfv=sess.run([cost,train,hf],feed_dict={x:trainData,y:trainTarget})
avgCost+=cv/totalBatch
pbar.set_description("cost:%f" % avgCost)
print("Evaluate:",sess.run(accuracy,feed_dict={x:testData, y:testTarget}))
>>>
Evaluate: 9.160306
모델 사용
#7 모델 사용
sess= tf.Session()
sess.run(tf.global_variables_initializer())
for epoch in range(trainingEpochs):
totalBatch = int(numIter(testData)/batch_size)
pbar = tqdm(range(totalBatch))
for i in pbar:
hfv = sess.run([hf],feed_dict={x:testData})
예측결과 시각화
#7 예측 시각화
xhat = testData
yhat = hfv[0]
%matplotlib notebook
plt.figure()
plt.plot(yhat, label = "predicted")
plt.plot(testTarget ,label = "actual")
plt.legend(prop={'size': 20})
'노트 > Python : 프로그래밍' 카테고리의 다른 글
| [케라스] 이미지 증식하기 코드 (1) | 2020.04.24 |
|---|---|
| [신경망] MNIST 데이터를 이용한 CNN모델 코드 (0) | 2020.04.23 |
| [케라스] 영화리뷰 긍정부정 분류하기 (0) | 2020.04.22 |
| [파이썬] 데이터시각화(2) (seaborn 패키지) (0) | 2020.04.22 |
| [신경망] 선형회귀로 분류가 불가능한 경우(XOR problem) (0) | 2020.04.21 |