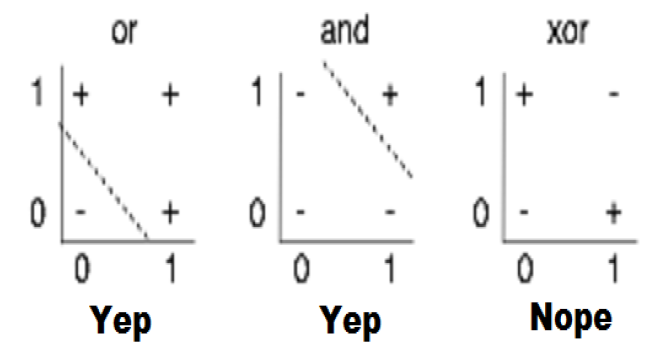
[신경망] 선형회귀로 분류가 불가능한 경우(XOR problem)
2020. 4. 21. 15:08ㆍ노트/Python : 프로그래밍
xdata = np.array([[0,0],[0,1],[1,0],[1,1]])
ydata = np.array([[0],[1],[1],[0]])텐서플로우 기반
단일 퍼셉트론
x = tf.placeholder(tf.float32, [None,2])
y = tf.placeholder(tf.float32, [None,1]) # 0~9 digit
w = tf.Variable(tf.random_normal([2,1]))
b = tf.Variable(tf.random_normal([1]))
hf= tf.sigmoid(tf.matmul(x, w) + b)
cost = -tf.reduce_mean(y * tf.log(hf) + (1 - y) * tf.log(1 - hf))
train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
predicted = tf.cast(hf > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, y), dtype=tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(10001):
_, cv, wv = sess.run(
[train, cost, w], feed_dict={x: xdata, y: ydata}
)
# if step % 1000 == 0:
# print(step, cv, wv)
h, c, a = sess.run([hf, predicted, accuracy], feed_dict={x: xdata, y: ydata})
print("\nHypothesis: ", h, "\nCorrect: ", c, "\nAccuracy: ", a)
>>
Hypothesis: [[0.5]
[0.5]
[0.5]
[0.5]]
Correct: [[0.]
[0.]
[0.]
[0.]]
Accuracy: 0.5
다중 퍼셉트론
NN for XOR
#1 히든 레이어
w1 = tf.Variable(tf.random_normal([2,2]))
b1 = tf.Variable(tf.random_normal([2]))
layer1 = tf.sigmoid(tf.matmul(x,w1)+b1)
#2 출력 레이어
w2 = tf.Variable(tf.random_normal([2,1]))
b2 = tf.Variable(tf.random_normal([1]))
hf = tf.sigmoid(tf.matmul(layer1,w2)+b2)
cost = -tf.reduce_mean(y * tf.log(hf) + (1 - y) * tf.log(1 - hf))
train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
predicted = tf.cast(hf > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, y), dtype=tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(10001):
_, cv = sess.run(
[train, cost], feed_dict={x: xdata, y: ydata}
)
# if step % 1000 == 0:
# print(step, cv, wv)
h, p, a = sess.run([hf, predicted, accuracy], feed_dict={x: xdata, y: ydata})
print("\nHypothesis: ", h, "\nPredicted: ", p, "\nAccuracy: ", a)
>>
Hypothesis: [[0.00853292]
[0.9895846 ]
[0.49738118]
[0.5045224 ]]
Predicted: [[0.]
[1.]
[0.]
[1.]]
Accuracy: 0.5
Deep NN for XOR
#1 히든 레이어
w1 = tf.Variable(tf.random_normal([2,2]))
b1 = tf.Variable(tf.random_normal([2]))
layer1 = tf.sigmoid(tf.matmul(x,w1)+b1)
#2 히든 레이어
w2 = tf.Variable(tf.random_normal([2,2]))
b2 = tf.Variable(tf.random_normal([2]))
layer2 = tf.sigmoid(tf.matmul(layer1,w2)+b2)
#3 출력 레이어
w3 = tf.Variable(tf.random_normal([2,1]))
b3 = tf.Variable(tf.random_normal([1]))
hf = tf.sigmoid(tf.matmul(layer2,w3)+b3)
cost = -tf.reduce_mean(y * tf.log(hf) + (1 - y) * tf.log(1 - hf))
train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
predicted = tf.cast(hf > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, y), dtype=tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(10001):
_, cv = sess.run(
[train, cost], feed_dict={x: xdata, y: ydata}
)
# if step % 1000 == 0:
# print(step, cv, wv)
h, p, a = sess.run([hf, predicted, accuracy], feed_dict={x: xdata, y: ydata})
print("\nHypothesis: ", h, "\nPredicted: ", p, "\nAccuracy: ", a)
>>
Hypothesis: [[0.01055897]
[0.66223466]
[0.6619525 ]
[0.66587406]]
Predicted: [[0.]
[1.]
[1.]
[1.]]
Accuracy: 0.75
Wide & Deep NN for XOR
#1 히든 레이어
w1 = tf.Variable(tf.random_normal([2,10]))
b1 = tf.Variable(tf.random_normal([10]))
layer1 = tf.sigmoid(tf.matmul(x,w1)+b1)
#2 히든 레이어
w2 = tf.Variable(tf.random_normal([10,10]))
b2 = tf.Variable(tf.random_normal([10]))
layer2 = tf.sigmoid(tf.matmul(layer1,w2)+b2)
#2 히든 레이어
w3 = tf.Variable(tf.random_normal([10,10]))
b3 = tf.Variable(tf.random_normal([10]))
layer3 = tf.sigmoid(tf.matmul(layer2,w3)+b3)
#3 출력 레이어
w4 = tf.Variable(tf.random_normal([10,1]))
b4 = tf.Variable(tf.random_normal([1]))
hf = tf.sigmoid(tf.matmul(layer3,w4)+b4)
cost = -tf.reduce_mean(y * tf.log(hf) + (1 - y) * tf.log(1 - hf))
train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
predicted = tf.cast(hf > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, y), dtype=tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(10001):
_, cv = sess.run(
[train, cost], feed_dict={x: xdata, y: ydata}
)
# if step % 1000 == 0:
# print(step, cv, wv)
h, p, a = sess.run([hf, predicted, accuracy], feed_dict={x: xdata, y: ydata})
print("\nHypothesis: ", h, "\nPredicted: ", p, "\nAccuracy: ", a)
Hypothesis: [[0.00128685]
[0.99926776]
[0.99835664]
[0.00178603]]
Predicted: [[0.]
[1.]
[1.]
[0.]]
Accuracy: 1.0
주의
히든레이어에는 relu함수를 사용한다.
sigmoid함수를 쓰면 계속 값이 작아지므로 정확하게 분류하지 못한다.
출력레이어에만 sigmoid 함수를 사용한다.
relu 함수 사용 결과
#1 히든 레이어
w1 = tf.Variable(tf.random_normal([2,10]))
b1 = tf.Variable(tf.random_normal([10]))
layer1 = tf.nn.relu(tf.matmul(x,w1)+b1)
#2 히든 레이어
w2 = tf.Variable(tf.random_normal([10,10]))
b2 = tf.Variable(tf.random_normal([10]))
layer2 = tf.nn.relu(tf.matmul(layer1,w2)+b2)
#2 히든 레이어
w3 = tf.Variable(tf.random_normal([10,10]))
b3 = tf.Variable(tf.random_normal([10]))
layer3 = tf.nn.relu(tf.matmul(layer2,w3)+b3)
#3 출력 레이어
w4 = tf.Variable(tf.random_normal([10,1]))
b4 = tf.Variable(tf.random_normal([1]))
hf = tf.sigmoid(tf.matmul(layer3,w4)+b4)
cost = -tf.reduce_mean(y * tf.log(hf) + (1 - y) * tf.log(1 - hf))
train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
predicted = tf.cast(hf > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, y), dtype=tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(10001):
_, cv = sess.run(
[train, cost], feed_dict={x: xdata, y: ydata}
)
# if step % 1000 == 0:
# print(step, cv, wv)
h, p, a = sess.run([hf, predicted, accuracy], feed_dict={x: xdata, y: ydata})
print("\nHypothesis: ", h, "\nPredicted: ", p, "\nAccuracy: ", a)
>>>
Hypothesis: [[1.5168486e-05]
[9.9997056e-01]
[9.9999356e-01]
[1.0745965e-05]]
Predicted: [[0.]
[1.]
[1.]
[0.]]
Accuracy: 1.0
Hypotesis 값이 각각 0과 1에 근접하게 분류되었음을 확인할 수 있다.
'노트 > Python : 프로그래밍' 카테고리의 다른 글
| [케라스] 영화리뷰 긍정부정 분류하기 (0) | 2020.04.22 |
|---|---|
| [파이썬] 데이터시각화(2) (seaborn 패키지) (0) | 2020.04.22 |
| [텐서플로우/케라스] MNIST 숫자 분류하기 (softmax) (0) | 2020.04.21 |
| [텐서플로우] 소프트맥스 회귀 (Softmax Regression) 분류 파이썬 코드 (0) | 2020.04.20 |
| [파이썬] 데이터시각화(1) (matplotlib.pyplot 패키지) (0) | 2020.04.20 |