[토픽모델링] LSA (Latent Similarity Analysis)를 이용한 토픽모델링 파이썬 코드
2020. 4. 9. 16:13ㆍ노트/Python : 프로그래밍
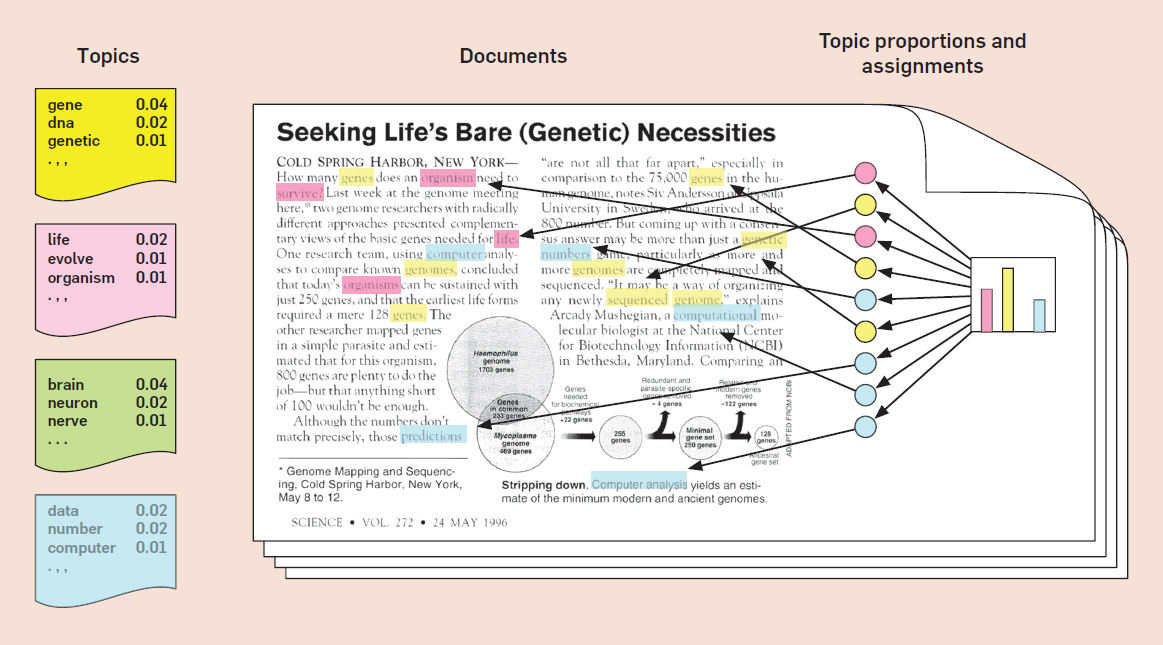
데이터 불러오기
from sklearn.datasets import fetch_20newsgroups
#20 가지의 서로다른 뉴스데이터
dataset=fetch_20newsgroups(shuffle=True, random_state=1, remove=("headers","footers","quotes"))
type(dataset) #sklearn.utils.Bunch
documents=dataset.data
len(documents) #11314건의 뉴스기사
print(type(documents)) #list
가공이 안된 law data이여서 데이터 전처리 과정이 필요
# 카테고리 확인
dataset.target_names
sklearn 패키지에서 분류해놓은 카테고리 ( 결과값 ),
토픽모델링을 하면 여기에 준하도록 데이터들이 분류가 되어야함
데이터 전처리
import pandas as pd
newsDf=pd.DataFrame({'documents':documents}) # 데이터 프레임으로 생성
newsDf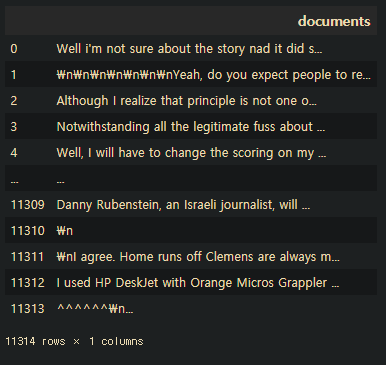
newsDf['documents'] # 시리즈함수에서는 문자열 함수 적용못함 (replace 못함)=> 문자열로 바꿔줘야함.
#특수문자 제거(영문자 제외)
newsDf['clean_doc']=newsDf['documents'].str.replace("[^a-zA-Z]"," ")
newsDf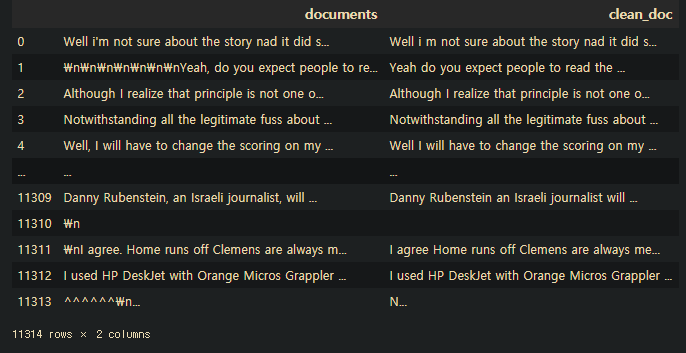
#3글자 이하 제거
newsDf['clean_doc']=newsDf['clean_doc'].apply(lambda x:' '.join([w for w in x.split() if len(w)>3]))
#소문자 변환
newsDf['clean_doc']=newsDf['clean_doc'].apply(lambda x:x.lower())
newsDf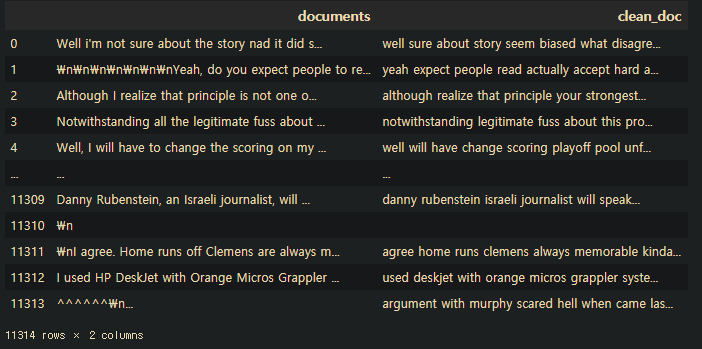
#불용어 제거
from nltk.corpus import stopwords
sw=stopwords.words('english')
#토큰화 (불용어적용을 위해)
tokenizedDoc=newsDf['clean_doc'].apply(lambda x: x.split())
tokenizedDoc=tokenizedDoc.apply(lambda x: [item for item in x if item not in sw ])
tokenizedDoc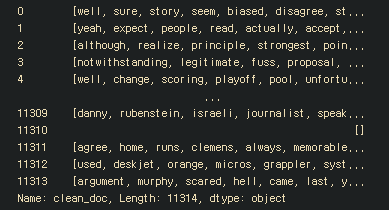
TF-IDF 매트릭스 구성
# TF-IDF는 토큰화가 안되어 있는 텍스트 데이터로 구성
# 토큰화 <-> 역토큰화 (토큰화 취소)
newsDf['clean_doc'][1]
deTokenizedDoc=[]
for i in range(len(newsDf)):
temp=" ".join(tokenizedDoc[i])
deTokenizedDoc.append(temp)
newsDf['clean_doc']=deTokenizedDoc
from sklearn.feature_extraction.text import TfidfVectorizer
vector=TfidfVectorizer(stop_words='english', max_features=1000) #최대 단어갯수
res=vector.fit_transform(newsDf['clean_doc'])
res.shape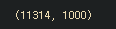
from sklearn.decomposition import TruncatedSVD
svdModel=TruncatedSVD(n_components=20)
svdModel.fit(res)
import numpy as np
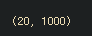
np.shape(svdModel.components_) #VT
#20개의 토픽과 1000개의 단어
terms=vector.get_feature_names() #1000개 단어
- 특이값 분해는 주어진 행렬이 U, s, VT 세개의 곱으로 나타내는 작업을 의미함.
3개 행렬을 곱하니 원래의 행렬이 나옴
S에 해당하는 부분은 토픽의 강도를 의미함 - 20개의 주제 , 1000개의 단어들 사용하기로함
truncated -svd : 차원축소의 효과
#토픽숫자: n_componets
토픽추출
def getTopic(c, fName, n=10):
for i, t in enumerate(c):
print("토픽 %d:" %(i+1), [(fName[i],t[i].round(5)) for i in t.argsort()[:-n-1:-1]])
getTopic(svdModel.components_,terms)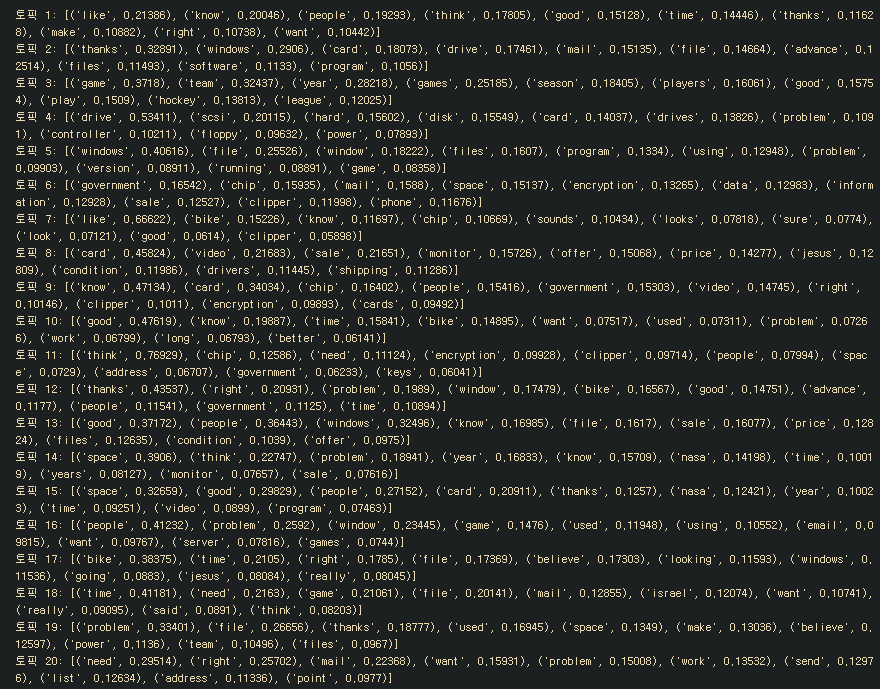
추출된 단어들을 가지고 토픽을 추론하면 됌.
토픽 2: [('thanks', 0.32891), ('windows', 0.2906), ('card', 0.18073), ('drive', 0.17461), ('mail', 0.15135), ('file', 0.14664), ('advance', 0.12514), ('files', 0.11493), ('software', 0.1133), ('program', 0.1056)]
나온걸로봐서 토픽2는 컴퓨터와 관련된 주제일 거다. 라고 생각해볼 수 있음.
'노트 > Python : 프로그래밍' 카테고리의 다른 글
| [파이썬기초] 문자열(str) 데이터 다루기 (0) | 2020.04.13 |
|---|---|
| [파이썬기초] 시계열 데이터 생성하기 (0) | 2020.04.13 |
| [추천시스템] 넷플릭스 영화 추천 시스템 구현 파이썬 코드 (13) | 2020.04.08 |
| [파이썬기초] 데이터전처리 중복값 처리 (0) | 2020.04.07 |
| [알고리즘] 영화 추천 시스템 코드 (1) | 2020.04.06 |